Overview of Supported EM Processes¶
In this section we provide a high-level overview of the EM processes supported by py_entitymatching. For more details, please read the document “How-To Guide to Entity Matching” (will soon be available from the package website).
Supported EM Problem Scenarios¶
Entity matching (EM) has many problem variations: matching two tables, matching within a single table, matching from a table into a knowledge base, etc. The package currently only support matching two tables. Specifically, given two tables A and B of relational tuples, find all tuple pairs (a in A, b in B) such that a and b refer to the same real-world entity. The following figure shows an example of matching persons between two given tables.
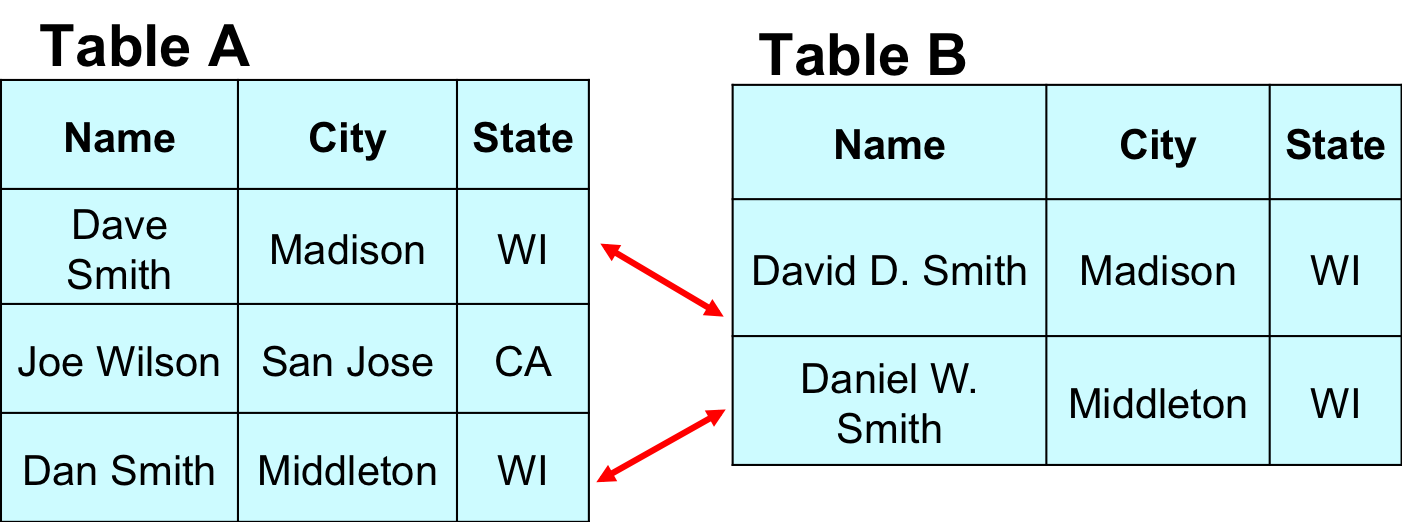
Of course, if you want to match tuples within a single table X, you can also use the package, by matching X with X (you do not have to create another copy of X, just provide X twice as the input if a command in the package requires two tables A and B as the input).
Two Fundamental Steps in the EM Process: Blocking and Matching¶
In practice, tables A and B can be quite large, such as having 100K tuples each, resulting in 10 billions tuple pairs across A and B. Trying to match all of these pairs is clearly very expensive. Thus, in such cases the user often employs domain heuristics to quickly remove obviously non-matched pairs, in a step called blocking, before matching the remaining pairs, in a step called matching.
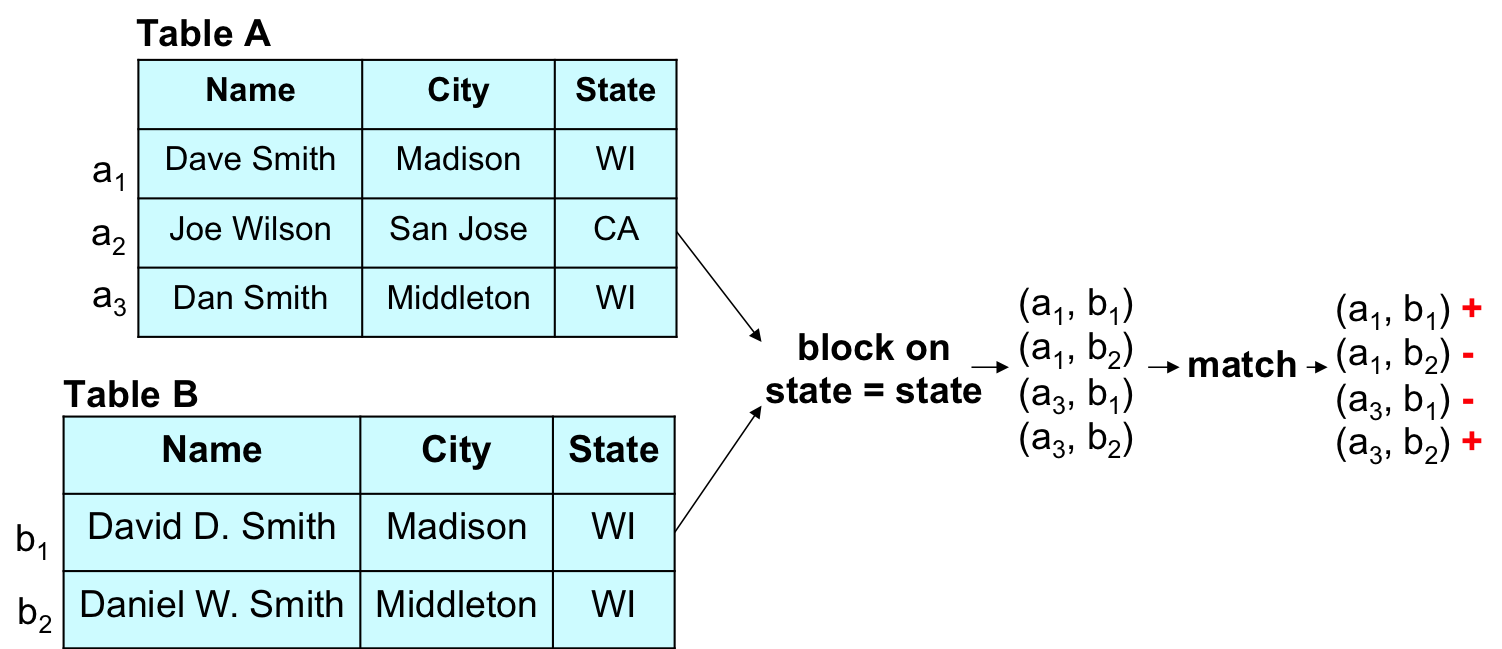
The following figure illustrates the above two fundamental steps. Suppose that we are matching the two tables A and B in (a), where each tuple describes a person. The blocking step can use a heuristic such as “if two tuples do not agree on state, then they cannot refer to the same person” to quickly remove all such tuple pairs (this is typically done using indexes, so the blocking step does not have to enumerate all tuple pairs between A and B). In other words, the blocking step retains only the four tuple pairs that agree on state, as shown in (b). The matching step in (c) then considers only these tuple pairs and predicts for each of them a label “match” or “not-match” (shown as “+” and “-” in the figure).
Supported EM Workflows¶
The current package supports EM workflows that consist of a blocking step followed by a matching step. Specifically, the package provides a set of blockers and a set of matchers (and the user can easily write his or her own blocker/matcher). Given two tables A and B to be matched, the user applies a blocker to the two tables to obtain a set of tuple pairs, then applies a matcher to these pairs to predict “match” or “no-match”. The user can use multiple blockers in the blocking step, and can combine them in flexible ways. The figure below illustrates both cases.

Further, the current package supports both rule-based and learning-based matchers. Specifically, rule-based matchers will require the user to write domain specific match rules and learning-based matchers will require the user to label a set of tuple pairs (as “match” or “no-match”), then use the labeled data to train matchers. In the future, we will consider extending the package to support more powerful EM workflows, such as using multiple matchers, or being able to add rules to process the output of the matchers.
The Development and Production Stages¶
In practice EM is typically carried out in two stages. In the development stage, the user tries to find an accurate EM workflow, often using data samples. In the production stage, the user then executes the discovered workflow on the entirety of data. The following figure illustrates the development stage, which is the focus of the current package. The figure also highlights the steps of the development stage that the current package supports.
In the figure, suppose we want to match two tables A and B, each having 1 million tuples. Trying to explore and discover an accurate workflow using these two tables would be too time consuming, because they are too big. Hence, the user will first “down sample” the two tables to obtain two smaller versions, shown as Tables A’ and B’ in the figure, each having 100K tuples, say (see the figure).
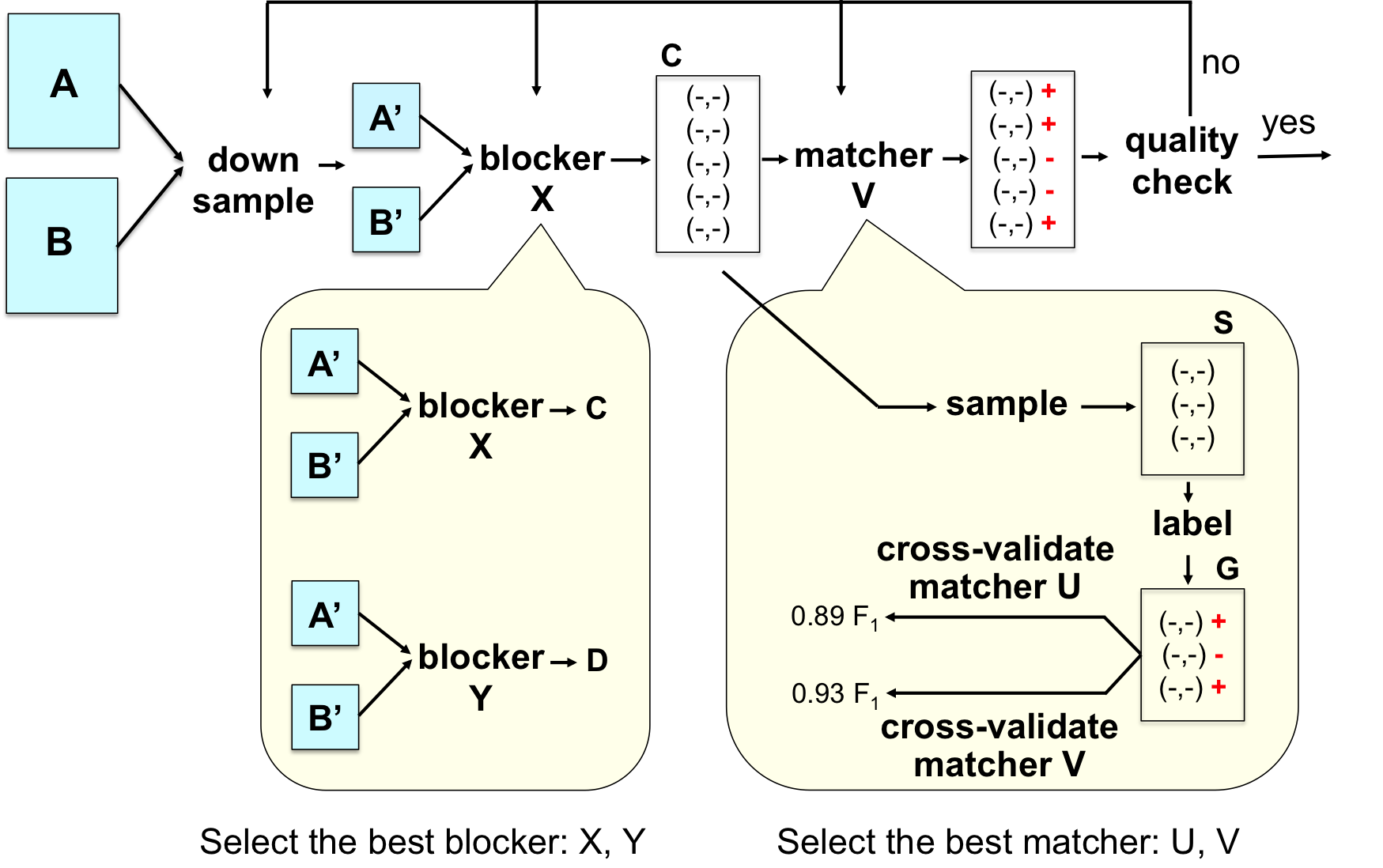
Next, suppose the package provides two blockers X and Y. Then the user will experiment with these blockers (for example, executing both on Tables A’ and B’ and examining their output) to select the blocker judged the best (according to some criterion). Suppose the user selects blocker X. Then next, he or she executes X on Tables A’ and B’ to obtain a set of candidate tuple pairs C.
Next, the user takes a sample S from C, and labels the pairs in S as “match” or “no-match” (see the figure). Let the labeled set be G, and suppose the package provides two matchers U and V. Suppose further that U and V are learning-based matchers (for example, one uses decision trees and the other uses logistic regression). Then in the next step, the user will use the labeled set G to perform cross validation for U and V. Suppose V produces higher matching accuracy (such as F1 score of 0.93, see the figure). Then the user will select V as the matcher, then apply V to the set C to predict “match” or “no-match”, shown as “+” or “-” in the figure. Finally, the user may perform quality check (by examining a sample of the predictions), then go back and debug and modify the previous steps as appropriate. This continues until the user is satisfied with the accuracy of the EM workflow.
Once the user has been satisfied with the EM workflow, the production stage begins. In this stage the user will execute the discovered workflow on the original tables A and B. Since these tables are very large, scaling is a major concern (and is typically solved using Hadoop or Spark). Other concerns include quality monitoring, exception handling, crash recovery, etc.
The Focus of the Current Package¶
The current py_entitymatching package focuses on helping the user with the development stage, that is, help him or her discover an accurate EM workflow. In the future, we will extend the package to also help the user with the production stage.