Specifying Blockers and Performing Blocking¶
In this section, we discuss how you can specify blockers and perform blocking.
Types of Blockers and Blocker Hierarchy¶
Once the tables are loaded and downsampled, most often you have to do blocking. Note that by blocking we mean to block a tuple pair from going through to the matching step. When applied to a tuple pair, a blocker returns True if the pair should be blocked. You must know conceptually the types of blockers and the blocker hierarchy in py_entitymatching to extend or modify them based on your need.
There are two types of blockers: (1) tuple-level, and (2) global. A tuple-level blocker can examine a tuple pair in isolation and decide if it should be admitted to the next stage. For example, an attribute equivalence blocker is a tuple-level blocker. A global blocker cannot make this decision in isolation. It would need to examine a set of other pairs as well. For example, a sorted neighborhood blocker applied over an union of the input tables is a global blocker. Currently, py_entitymatching supports only tuple-level blockers.
The blockers can be combined in complex ways, such as
apply blocker b1 to the two tables
apply blocker b2 to the two tables
apply blocker b3 to the output of b1
Further, you may just want to apply a blocker to just a pair of tuples, to see how the blocker works.
In py_entitymatching, there is a Blocker class from which a set of concrete blockers are inherited. These concrete blockers implement the following methods:
block_tables (apply to input tables A and B)
block_candset (apply to an output from another blocker (e.g. table C))
block_tuples (apply to a tuple pair to check if it will survive blocking)
In py_entitymatching, there are four concrete blockers implemented: (1) attribute equivalence blocker, (2) overlap blocker, (3) rule-based blocker, and (4) black box blocker. All the functions implemented in the concrete blockers are metadata aware.
The class diagram of Blocker and the concrete blockers inherited from it is shown below:
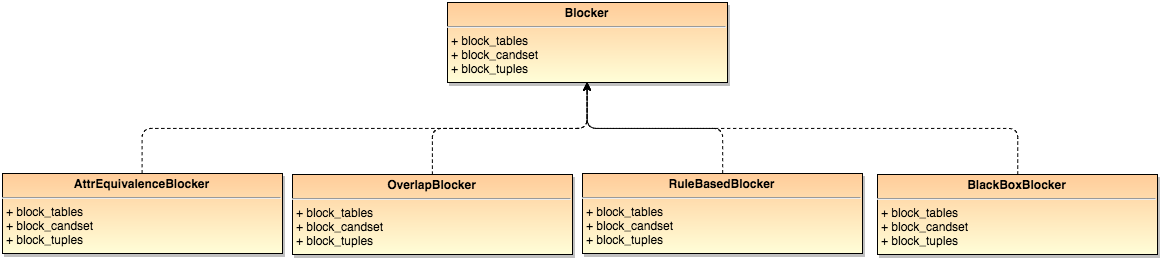
Built-In Blockers¶
Built-in blockers are those that have been built into py_entitymatching and you can just simply call them. py_entitymatching currently offers three built-in blockers.
Attribute Equivalence Blocker
Given two tables A and B, conceptually, block_tables in attribute equivalence blocker takes an attribute x of table A, an attribute y of table B, and returns True (that is, drop the tuple pair) if x and y are not of the same value.
An example of using the above function is shown below:
>>> import py_entitymatching as em
>>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID')
>>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID')
>>> ab = em.AttrEquivalenceBlocker()
>>> C = ab.block_tables(A, B, 'zipcode', 'zipcode', l_output_attrs=['name'], r_output_attrs=['name'])
Please look at the API reference of block_tables()
for more details.
The function block_candset is similar to block_tables except block_candset is applied to the candidate set, i.e. the output from block_tables. An example of using block_candset is shown below:
>>> D = ab.block_candset(C, 'age', 'age')
Please look at the API reference of block_candset()
for more details.
The function block_tuples is used to check if a tuple pair would get blocked. An example of using block_tuples is shown below:
>>> status = ab.block_tuples(A.ix[0], B.ix[0], 'age', 'age')
>>> status
True
Please look at the API reference of block_tuples()
for more details.
Overlap Blocker
Given two tables A and B, conceptually, block_tables in overlap blocker takes an attribute x of table A, an attribute y of table B, and returns True (that is, drop the tuple pair) if x and y do not share any token (where the token is a word or a q-gram).
As part of the pre-processing for this blocker, the strings are first converted to lowercase.
An example of using block_tables is shown below:
>>> import py_entitymatching as em
>>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID')
>>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID')
>>> ob = em.OverlapBlocker()
>>> C = ob.block_tables(A, B, 'zipcode', 'zipcode', overlap_size=1, l_output_attrs=['name'], r_output_attrs=['name'] )
Please look at the API reference of block_tables()
for more details.
The function block_candset is similar to block_tables except block_candset is applied to the candidate set, i.e. the output from block_tables.
An example of using block_candset is shown below:
>>> D = ob.block_candset(C, 'age', 'age')
Please look at the API reference of block_candset()
for more details.
The function block_tuples is used to check if a tuple pair would get blocked. An example of using block_tuples is shown below:
>>> status = ob.block_tuples(A.ix[0], B.ix[0], 'name', 'name', overlap_size=1)
>>> status
True
Please look at the API reference of block_tuples()
for more details.
Sorted Neighborhood Blocker
WARNING: THIS IS AN EXPERIMENTAL COMMAND. THIS COMMAND IS NOT TESTED. USE AT YOUR OWN RISK.
Given two tables A and B, conceptually, block_tables works in the following manner. First, for table A, block_tables creates a blocking attribute for every tuple using the output of l_block_attr. Next, for table B, block_tables similarly creates a blocking attribute using the output of r_block_attr. Then, tables A and B are combined and sorted on the blocking attribute.
Finally, a sliding window of size window_size is passed through the sorted dataset. If two tuples are within window_size positions of each other in sorted order, and the two tuples come from different tables, then the two tuples are returned in the candidate set.
An example of using block_tables is shown below:
>>> import py_entitymatching as em
>>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID')
>>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID')
>>> sn = em.SortedNeighborhoodBlocker()
>>> C = sn.block_tables(A, B, l_block_attr='zipcode', r_block_attr='zipcode', l_output_attrs=['name'], r_output_attrs=['name'], window_size=3 )
Please look at the API reference of block_tables()
for more details.
Unlike the other two blockers, since the sorted neighborhood blocker requires the sorted order of all tuples in the database, block_candset and block_tuples are not applicable and will raise an assertion if called.
Two things to note. First, consider the trade-off of possible values to window_size. If the size is too small, actually-matching tuples will not be returned in the candidate set (and thus, missed). If the window size is very large, the resulting candidate set will also be excessively large, hurting performance. The exact size needed is unique to each dataset.
Second, if window_size is smaller than a range of matching tuples, and actually-matching tuples will be missed, not be returned in the candidate set. However, if the blocking attribute is not sufficient to make a unique sorted order, than the resulting sorted order is one of a set of potential sorted orders. If the method of sorting changes, for instance if more cores are used, a different sorted order may be returned. This sorted order may result in a different candidate set being returned. To avoid this situation it is recommended to add some uniqueness into the blocking attribute (such as the ID), so that there is only one correct sorted order. This will help ensure the same set of results are returned from the same inputs. An example of this is:
>>> A["birth_year_plus_id"]=A["birth_year"].map(str)+'-'+A["ID"].map(str)
>>> B["birth_year_plus_id"]=B["birth_year"].map(str)+'-'+A["ID"].map(str)
>>> C3 = sn.block_tables(A, B, l_block_attr='birth_year_plus_id', r_block_attr='birth_year_plus_id', l_output_attrs=['name', 'birth_year_plus_id', 'birth_year', 'zipcode'], r_output_attrs=['name', 'birth_year_plus_id', 'birth_year', 'zipcode'], l_output_prefix='l_', r_output_prefix='r_', window_size=5)
In this example a new attribute birth_year_plus_id is used as the blocking attribute, and will always have the same sorted order.
Blackbox Blockers¶
By blackbox blockers we mean that the user supplies a Python function which encodes blocking for a tuple pair. Specifically, the Python function will take in two tuples and returns True if the tuple pair needs to be blocked, else returns False. To use a blackbox blocker, first you must write a blackbox blocker function.
An example of blackbox blocker function is shown below:
def match_last_name(ltuple, rtuple):
# assume that there is a 'name' attribute in the input tables
# and each value in it has two words
l_last_name = ltuple['name'].split()[1]
r_last_name = rtuple['name'].split()[1]
if l_last_name != r_last_name:
return True
else:
return False
Then instantiate a blackbox blocker and set the blocking function function as follows:
>>> import py_entitymatching as em
>>> bb = em.BlackBoxBlocker()
>>> bb.set_black_box_function(match_last_name)
Now, you can call block_tables on the input tables. Conceptually, block_tables would apply the blackbox blocker function on the Cartesian product of the input tables A and B, and return a candidate set of tuple pairs.
An example of using block_tables is shown below:
>>> C = bb.block_tables(A, B, l_output_attrs=['name'], r_output_attrs=['name'] )
Please look at the API reference of block_tables()
for more details.
The function block_candset is similar to block_tables except block_candset is applied to the candidate set, i.e. the output from block_tables.
An example of using block_candset is shown below:
>>> D = bb.block_candset(C)
Please look at the API reference of block_candset()
for more details.
Further, block_tuples is used to check if a tuple pair would get blocked. An example of using block_tuples is shown below:
>>> status = bb.block_tuples(A.ix[0], B.ix[0])
>>> status
True
Please look at the API reference of block_tuples()
for more details.
Rule-Based Blockers¶
You can write a few domain specific rules (for blocking purposes) using rule-based blocker. If you want to write rules, then you must start by defining a set of features. Each feature is a function that when applied to a tuple pair will return a numeric value. We will discuss how to create a set of features in the section Creating Features for Blocking.
Once the features are created, py_entitymatching stores this set of features in a feature table. We refer to this feature table as block_f. Then you will be able to instantiate a rule-based blocker and add rules like this:
>>> rb = em.RuleBasedBlocker()
>>> rb.add_rule(rule1, block_f)
>>> rb.add_rule(rule2, block_f)
In the above, block_f is a set of features stored as a Dataframe (see section Creating Features for Blocking).
Each rule is a list of strings. Each string specifies a conjunction of predicates. Each predicate has three parts: (1) an expression, (2) a comparison operator, and (3) a value. The expression is evaluated over a tuple pair, producing a numeric value. Currently, in py_entitymatching an expression is limited to contain a single feature (being applied to a tuple pair). So an example predicate will look like this:
name_name_lev(ltuple, rtuple) > 3
In the above name_name_lev is feature. Concretely, this feature computes Levenshtein distance between the name values in the input tuple pair.
As an example, the rules rule1 and rule2 can look like this:
rule1 = ['name_name_lev(ltuple, rtuple) > 3', 'age_age_exact_match(ltuple, rtuple) !=0']
rule2 = ['address_address_lev(ltuple, rtuple) > 6']
In the above, rule1 contains two predicates and rule2 contains just a single predicate. Each rule is a conjunction of predicates. That is, each rule will return True only if all the predicates return True. The blocker is then a disjunction of rules. That is, even if one of the rules return True, then the tuple pair will be blocked.
Once the rules are specified, you can call block_tables on the input tables. Conceptually, block_tables would apply the rule-based blocker function on the Cartesian product of the input tables A and B and return a candidate set of tuple pairs.
An example of using block_tables is shown below:
>>> C = rb.block_tables(A, B, l_output_attrs=['name'], r_output_attrs=['name'] )
Please look at the API reference of block_tables()
for more details.
The function block_candset is similar to block_tables except block_candset is applied to the candidate set, i.e. the output from block_tables.
An example of using block_candset is shown below:
>>> D = rb.block_candset(C)
Please look at the API reference of block_candset()
for more details.
The function block_tuples is used to check if a tuple pair would get blocked. An example of using block_tuples is shown below:
>>> status = rb.block_tuples(A.ix[0], B.ix[0])
>>> status
True
Please look at the API reference of block_tuples()
for more details.
Combining Multiple Blockers¶
If you use multiple blockers, then you have to combine them to get a consolidated candidate set. There are many different ways to combine the candidate sets such as doing union, majority vote, weighted vote, etc. Currently, py_entitymatching only supports union-based combining.
In py_entitymatching, combine_blocker_outputs_via_union is used to do union-based combining.
An example of using combine_blocker_outputs_via_union is shown below:
>>> import py_entitymatching as em
>>> ab = em.AttrEquivalenceBlocker()
>>> C = ab.block_tables(A, B, 'zipcode', 'zipcode')
>>> ob = em.OverlapBlocker()
>>> D = ob.block_candset(C, 'address', 'address', overlap_size=1)
>>> block_f = em.get_features_for_blocking(A, B)
>>> rb = em.RuleBasedBlocker()
>>> rule = ['name_name_lev(ltuple, rtuple) > 6']
>>> rb.add_rule(rule, block_f)
>>> E = rb.block_tables(A, B)
>>> F = em.combine_blocker_outputs_via_union([C, E])
Conceptually, the command takes in a list of blocker outputs (i.e. pandas Dataframes) and produces a consolidated table. The output table contains the union of tuple pair ids and other attributes from the input list.
Please look at the API reference of combine_blocker_outputs_via_union()
for more details.