User Manual for py_entitymatching¶
This document explains how to install and use the package. To contribute to the package, see the project website, section “For Contributors and Developers”.
Contents¶
What is New?¶
- Compared to Version 0.3.1, the followings are new:
Cython version was updated. The package is now built with updated Cython version >= 0.27.3.
Added support for Python 3.7 version and dropped Testing support for Python 3.4 version.
Installation¶
Requirements¶
Python 2.7 or Python 3.5+
Platforms¶
py_entitymatching has been tested on Linux (Redhat enterprise Linux with 2.6 .32 kernel), OS X (Sierra), and Windows 10.
Dependencies¶
pandas (provides data structures to store and manage tables)
scikit-learn (provides implementations for common machine learning algorithms)
joblib (provides multiprocessing capabilities)
pyqt5 (provides tools to build GUIs)
py_stringsimjoin (provides implementations for string similarity joins)
py_stringmatching (provides a set of string tokenizers and string similarity functions)
cloudpickle (provides functions to serialize Python constructs)
pyprind (library to display progress indicators)
pyparsing (library to parse strings)
six (provides functions to write compatible code across Python 2 and 3)
xgboost (provides an implementation for xgboost classifier)
pandas-profiling (provides implementation for profiling pandas dataframe)
pandas-table (provides data exploration tool for pandas dataframe)
openrefine (provides data exploration tool for tables)
ipython (provides better tools for displaying tables in notebooks)
scipy (dependency for skikit-learn)
C Compiler Required¶
Installing Using conda Before installing this package, you need to make sure that you have a C compiler installed. This is necessary because this package contains Cython files. Go here for more information about how to check whether you already have a C compiler and how to install a C compiler. After you have confirmed that you have a C compiler installed, you are ready to install py_entitymatching.
Installing Using pip¶
To install the package using pip, execute the following command:
pip install -U numpy scipy py_entitymatching
The above command will install py_entitymatching and all of its dependencies except XGBoost, pandastable, openrefine, and PyQt5. This is because pip can only install the dependency packages that are available in PyPI and PyQt5, XGBoost, pandastable are not in PyPI for Python 2.
Installing from Source Distribution¶
Clone the py_entitymatching package from GitHub
Then, execute the following commands from the package root:
pip install -U numpy scipy
python setup.py install
which installs py_stringmatching into the default Python directory on your machine. If you do not have installation permission for that directory then you can install the package in your home directory as follows:
python setup.py install --user
For more information see this StackOverflow link.
The above commands will install py_entitymatching and all of its dependencies, except PyQt5 and XGBoost.
This is because, similar to pip, setup.py can only install the dependency packages that are available in PyPI and PyQt5, pandastable, XGBoost are not in PyPI for Python 2.
To install PyQt5, follow the instructions at this page.
To install XGBoost, follow the instructions at this page.
To install pandastable follow the instructions at this page.
To install openrefine follow the instructions at this page.
Note
Currently, py_entitymatching supports a set of experimental commands that help users create an EM workflow. Some of these commands will require installing Dask. To install dask refer to this `page <http://dask.pydata.org/en/latest/install.html`_.
Overview of Supported EM Processes¶
In this section we provide a high-level overview of the EM processes supported by py_entitymatching. For more details, please read the document “How-To Guide to Entity Matching” (will soon be available from the package website).
Supported EM Problem Scenarios¶
Entity matching (EM) has many problem variations: matching two tables, matching within a single table, matching from a table into a knowledge base, etc. The package currently only support matching two tables. Specifically, given two tables A and B of relational tuples, find all tuple pairs (a in A, b in B) such that a and b refer to the same real-world entity. The following figure shows an example of matching persons between two given tables.
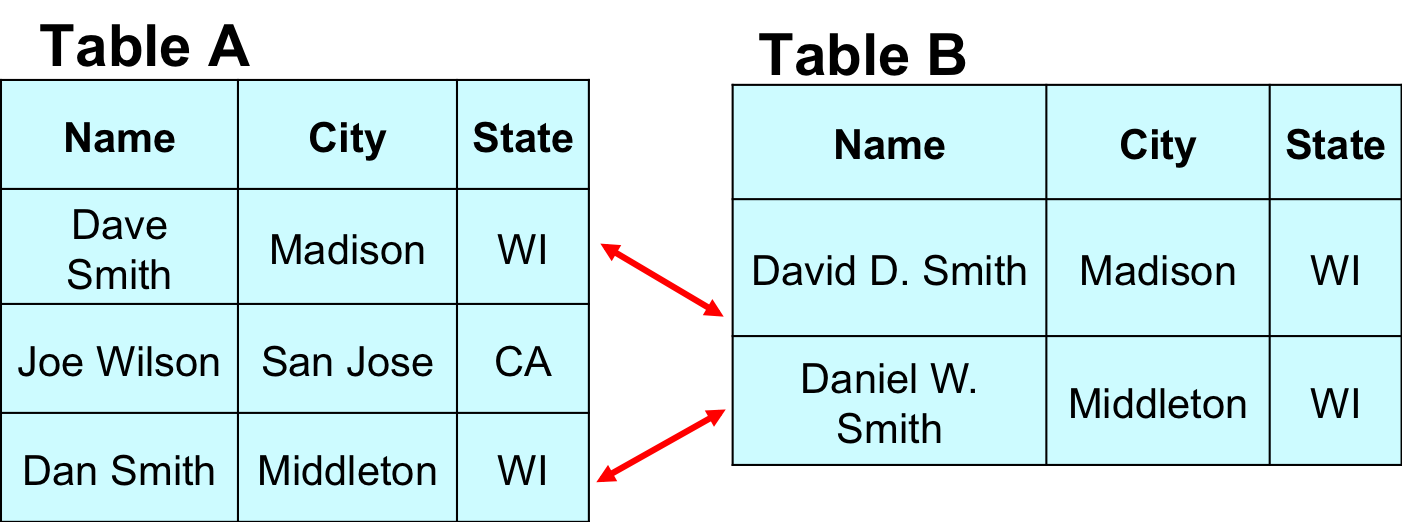
Of course, if you want to match tuples within a single table X, you can also use the package, by matching X with X (you do not have to create another copy of X, just provide X twice as the input if a command in the package requires two tables A and B as the input).
Two Fundamental Steps in the EM Process: Blocking and Matching¶
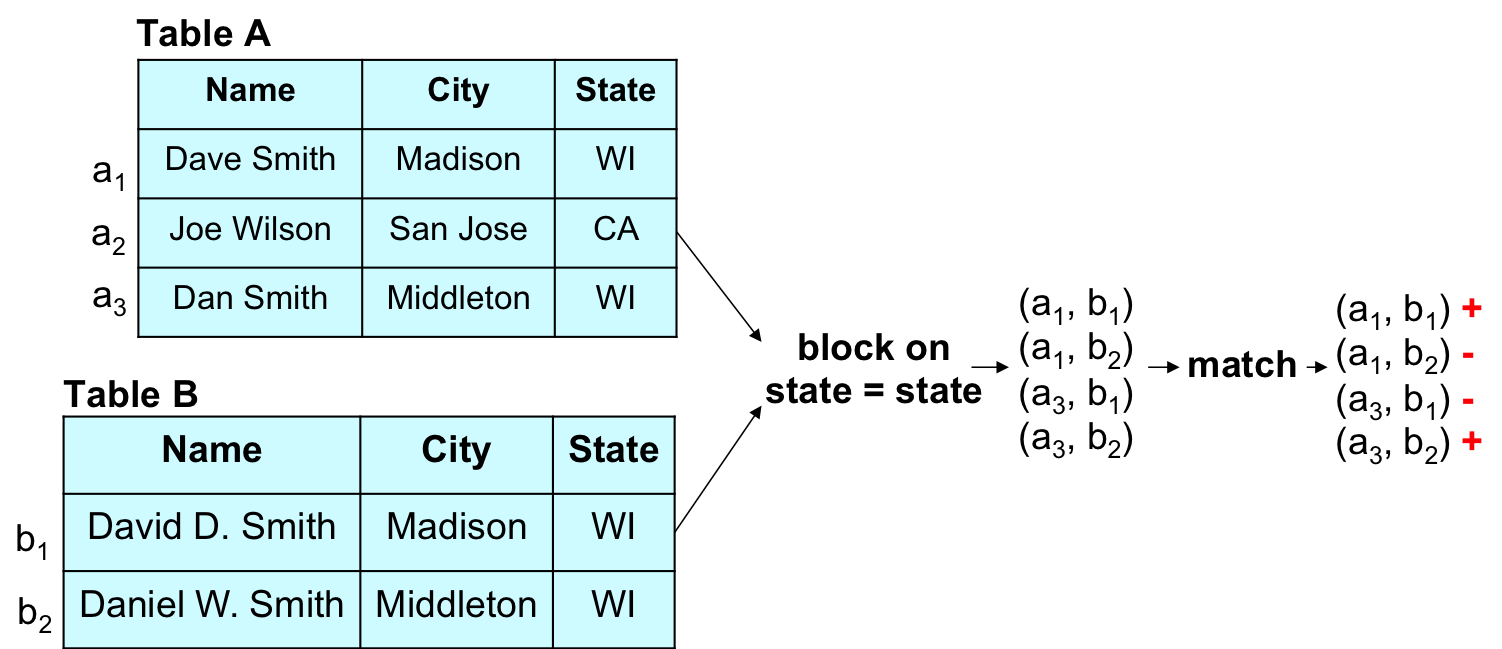
In practice, tables A and B can be quite large, such as having 100K tuples each, resulting in 10 billions tuple pairs across A and B. Trying to match all of these pairs is clearly very expensive. Thus, in such cases the user often employs domain heuristics to quickly remove obviously non-matched pairs, in a step called blocking, before matching the remaining pairs, in a step called matching.
The following figure illustrates the above two fundamental steps. Suppose that we are matching the two tables A and B in (a), where each tuple describes a person. The blocking step can use a heuristic such as “if two tuples do not agree on state, then they cannot refer to the same person” to quickly remove all such tuple pairs (this is typically done using indexes, so the blocking step does not have to enumerate all tuple pairs between A and B). In other words, the blocking step retains only the four tuple pairs that agree on state, as shown in (b). The matching step in (c) then considers only these tuple pairs and predicts for each of them a label “match” or “not-match” (shown as “+” and “-” in the figure).
Supported EM Workflows¶
The current package supports EM workflows that consist of a blocking step followed by a matching step. Specifically, the package provides a set of blockers and a set of matchers (and the user can easily write his or her own blocker/matcher). Given two tables A and B to be matched, the user applies a blocker to the two tables to obtain a set of tuple pairs, then applies a matcher to these pairs to predict “match” or “no-match”. The user can use multiple blockers in the blocking step, and can combine them in flexible ways. The figure below illustrates both cases.

Further, the current package supports both rule-based and learning-based matchers. Specifically, rule-based matchers will require the user to write domain specific match rules and learning-based matchers will require the user to label a set of tuple pairs (as “match” or “no-match”), then use the labeled data to train matchers. In the future, we will consider extending the package to support more powerful EM workflows, such as using multiple matchers, or being able to add rules to process the output of the matchers.
The Development and Production Stages¶
In practice EM is typically carried out in two stages. In the development stage, the user tries to find an accurate EM workflow, often using data samples. In the production stage, the user then executes the discovered workflow on the entirety of data. The following figure illustrates the development stage, which is the focus of the current package. The figure also highlights the steps of the development stage that the current package supports.
In the figure, suppose we want to match two tables A and B, each having 1 million tuples. Trying to explore and discover an accurate workflow using these two tables would be too time consuming, because they are too big. Hence, the user will first “down sample” the two tables to obtain two smaller versions, shown as Tables A’ and B’ in the figure, each having 100K tuples, say (see the figure).
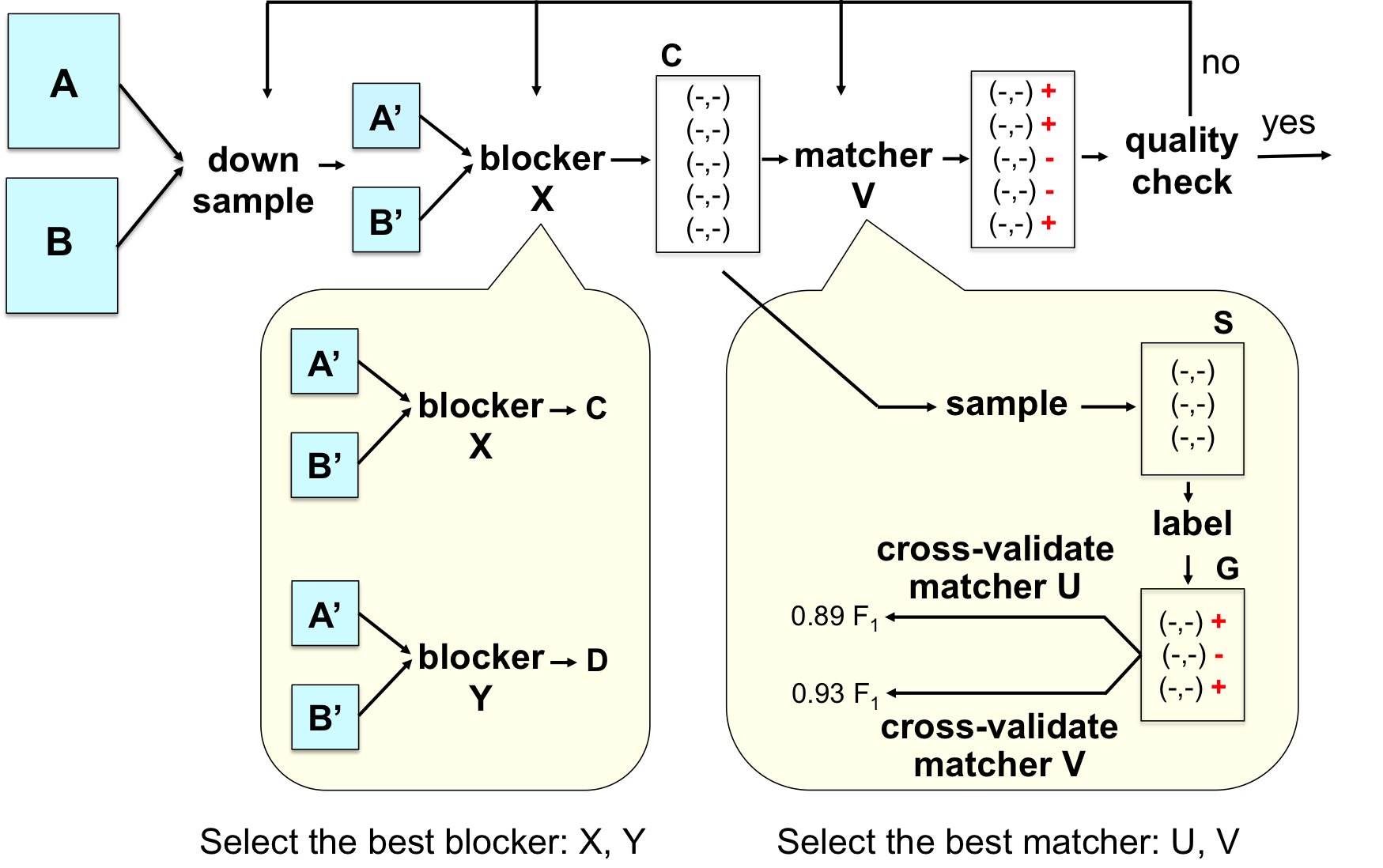
Next, suppose the package provides two blockers X and Y. Then the user will experiment with these blockers (for example, executing both on Tables A’ and B’ and examining their output) to select the blocker judged the best (according to some criterion). Suppose the user selects blocker X. Then next, he or she executes X on Tables A’ and B’ to obtain a set of candidate tuple pairs C.
Next, the user takes a sample S from C, and labels the pairs in S as “match” or “no-match” (see the figure). Let the labeled set be G, and suppose the package provides two matchers U and V. Suppose further that U and V are learning-based matchers (for example, one uses decision trees and the other uses logistic regression). Then in the next step, the user will use the labeled set G to perform cross validation for U and V. Suppose V produces higher matching accuracy (such as F1 score of 0.93, see the figure). Then the user will select V as the matcher, then apply V to the set C to predict “match” or “no-match”, shown as “+” or “-” in the figure. Finally, the user may perform quality check (by examining a sample of the predictions), then go back and debug and modify the previous steps as appropriate. This continues until the user is satisfied with the accuracy of the EM workflow.
Once the user has been satisfied with the EM workflow, the production stage begins. In this stage the user will execute the discovered workflow on the original tables A and B. Since these tables are very large, scaling is a major concern (and is typically solved using Hadoop or Spark). Other concerns include quality monitoring, exception handling, crash recovery, etc.
The Focus of the Current Package¶
The current py_entitymatching package focuses on helping the user with the development stage, that is, help him or her discover an accurate EM workflow. In the future, we will extend the package to also help the user with the production stage.
Guides¶
The goal of this page is to give you some concrete examples for using py_entitymatching. These are examples with sample data that is already bundled along with the package. The examples are in the form of Jupyter notebooks.
A Quick Tour of Jupyter Notebook¶
This tutorial gives a quick tour on installing and using Jupyter notebook.
End-to-End EM Workflows¶
EM workflow with blocking using a overlap blocker and matching using Random Forest matcher: Jupyter notebook
EM workflow with blocking using a overlap blocker, selecting among multiple matchers, using the selected matcher to predict matches, and evaluating the predicted matches: Jupyter notebook
EM workflow with blocking using multiple blockers (overlap and attribute equivalence blocker), debugging the blocker output, selecting among multiple matchers, debugging the matcher output, using the selected matcher to predict matches, and evaluating the predicted matches: Jupyter notebook
Stepwise Guides¶
Reading CSV files from disk: Jupyter notebook
Down sampling: Jupyter notebook
Data profiling: Jupyter notebook
Data exploration: Jupyter notebook
Blocking:
Using overlap blocker: Jupyter notebook
Using attribute equivalence blocker: Jupyter notebook
Using rule-based blocker: Jupyter notebook
Using blackbox blocker: Jupyter notebook
Combining multiple blockers: Jupyter notebook
Debugging blocker output: Jupyter notebook
Handling features:
Generating features manually: Jupyter notebook
Editing attribute types and generating features manually: Jupyter notebook
Adding features to feature table: Jupyter notebook
Removing features from feature table: Jupyter notebook
Sampling and labeling: Jupyter notebook
Matching:
Selecting the best learning-based matcher (involves splitting the labeled data, generating features, instantiating multiple matchers, debugging the matcher output): Jupyter notebook
Performing matching using rule-based matcher: Jupyter notebook
Improving matching results using triggers: Jupyter notebook
Evaluating the predictions from a matcher: Jupyter notebook
Data Structures¶
In py_entitymatching, we will need to store many tables and metadata associated with it. It is important for you to know the data structures that are used to store the tables and the metadata, so that you can manipulate them based on your need.
As a convention, we will use:
A and B to refer to the original two tables to be matched,
C to refer to the candidate set table obtained from A and B after the blocking step,
S to refer to a sample taken from C, and
G to refer to a table that contains the tuple pairs in S and a golden label for each pair (indicating the pair as matches or non-matches).
Storing Tables Using Pandas Dataframes¶
We will need to store a lot of data as tables in py_entitymatching. We use pandas Dataframes to represent tables (you can read more about pandas and pandas Dataframes here).
Tuple: We often refer to a row of a table as tuple. Each tuple is just a row in a Dataframe and this is of type pandas Series (you can read more about pandas Series here).
Storing Metadata Using a Catalog¶
Bare Minimum that You Should Know: In py_entitymatching, we need to store a lot of metadata with a table such as key and foreign key. We use a new data structure, Catalog, to store metadata. You need not worry about instantiating this object (it gets automatically instantiated when py_entitymatching gets loaded in Python memory) or manipulating this object directly.
All the py_entitymatching commands correctly handle the metadata in the Catalog, and for you, there are commands to manipulate the Catalog (please see Handling Metadata section for the supported commands).
If You Want to Read More: As we mentioned earlier, we need to store a lot of metadata with a table. Here are a few examples:
Each table in py_entitymatching should have a key, so that we can easily identify the tuples. Keys are also critical later for debugging, provenance, etc. Key is a metadata that we want to store for a table.
The blocking step will create tuple pairs from two tables A and B. For example, suppose we have table A(aid, a, b) and table B(bid, x, y), then the tuple pairs can be stored in a candidate set table C(cid, aid, bid, a, b, x, y). This table could be very big, taking up a lot of space in memory. To save space, we may want to just store C as C(cid, aid, bid) and then have pointers back to tables A and B. The two pointers back to A and B are metadata that we may want to store for table C. Specifically, the metadata for C include key (cid) and foreign keys (aid, bid) to the base tables (A, B).
There are many other examples of metadata that we may want to store for a table. Though pandas Dataframes is a good choice for storing data as tables, it does not provide a robust way to store metadata (for more discussion on this topic, please look at this thread). To tackle this, we have a new data structure, Catalog to store the metadata for tables.
Conceptually, Catalog is a dictionary, where the keys are unique identifiers for each Dataframe and the values are dictionaries containing metadata. This dictionary can have different kinds of keys that point to metadata. Examples of such keys are:
key: the name of the key attribute of the table.
ltable: pointer to the left table (see below).
rtable: pointer to the right table (see below).
The kind of metadata stored for a table would depend on the table itself. For example, the input tables must have a key and this can be the only metadata.
But, if we consider table C (which is obtained by performing blocking on input tables A and B), this table can be very large, so we typically represent it using a view over two tables A and B. Such a table C will have the following attributes:
_id (key attribute of table C).
ltable_aid (aid is the key attribute in table A).
rtable_bid (bid is the key attribute in table B).
some attributes from A and B.
The metadata dictionary for table C will have at least these fields:
key: _id.
ltable: points to table A.
rtable: points to table B.
fk_ltable: ltable_aid (that is, ltable.aid is a foreign key of table A).
fk_rtable: rtable_bid.
Summary¶
Tables in py_entitymatching are represented as pandas Dataframes.
The metadata for tables are stored in a separate data structure called Catalog.
The kind of metadata stored will depend on the table (for example input table will have key, and the table from blocking will have key, ltable, rtable, fk_table, fk_rtable).
So there are five reserved keywords for metadata: key, ltable, rtable, fk_ltable, fk_rtable. You should not use these names to store metadata for other application specific purposes.
Steps of Supported EM Workflows¶
Reading the CSV Files from Disk¶
Currently, py_entitymatching only asupports reading CSV files from disk.
The Minimal That You Should Do: First, you must store the input tables as CSV files in disk. Please look at section CSV Format to learn more about CSV format. An example of a CSV file will look like this:
ID, name, birth_year, hourly_wage, zipcode
a1, Kevin Smith, 1989, 40, 94107
a2, Michael Franklin, 1988, 27.5, 94122
a3, William Bridge, 1988, 32, 94121
Next, each table in py_entitymatching must have a key column. If the table already has a key column, then you can read the CSV file and set the key column as like this:
# ID is the key column in table.csv
>>> A = em.read_csv_metadata('path_to_csv_dir/table.csv', key='ID')
If the table does not have a key column, then you can read the CSV file, add a key column and set the added key column like this:
# Read the CSV file
>>> A = em.read_csv_metadata('path_to_csv_dir/table.csv')
# Add a key column with name 'ID'
>>> A['ID'] = range(0, len(A))
# Set 'ID' as the key column
>>> em.set_key(A, 'ID')
If You Want to Read and Play Around More: In general, the command
read_csv_metadata() looks for a file (with the same file name
as the CSV file) with .metadata extension in the same directory containing the
metadata. If the file containing metadata information is not present, then
read_csv_metadata() will proceed just reading the CSV file
as mentioned in the command.
To update the metadata for a table, using a metadata file, first, you must manually create
this file and specify the metadata for a table and then call
read_csv_metadata(). The command will automatically read the metadata from the
file and update the Catalog.
For example, if you read table.csv then read_csv_metadata()
looks for table.metadata file. The contents of table.metadata may look like this:
#key=ID
Each line in the file starts with #. The metadata is written as key=value pairs, one in each line. The contents of the above file says that ID is the key attribute (for the table in the file table.csv).
The table mentioned in the above example along with the metadata file stored in the same directory can be read as follows:
>>> import py_entitymatching as em
>>> A = em.read_csv_metadata('path_to_csv_dir/table.csv')
Once, the table is read, you can check to see which
attribute of the table is a key using get_key() command as
shown below:
>>> em.get_key(A)
'ID'
As you see, the key for the table is updated correctly as ‘ID’.
See read_csv_metadata() for more details.
Down Sampling¶
Once the tables to be matched are read, they must be down sampled if the number of tuples in them are large (for example, 100K+ tuples). This is because working with large tables can be very time consuming (as any operation performed would have to process these large tables).
Random sampling however does not work, because the sampled may end up sharing very few matches, especially if the number of matches between the input tables are small to begin with.
In py_entitymatching, you can use sample the input tables using down_sample command. This command samples the input tables intelligently that ensures a reasonable number of matches between them.
If A and B are the input tables, then you can use down_sample command as shown below:
>>> sample_A, sample_B = em.down_sample(A, B, size=500, y_param=1)
Conceptually, the command takes in two original input tables, A, B (and some parameters), and produces two sampled tables, sample_A and sample_B. Specifically, you must set the size to be the number of tuples that should be sampled from B (this will be the size of sample_B table) and set the y_param to be the number of tuples to be selected from A (for each tuple in sample_B table). The command internally uses a heuristic to ensure a reasonable number of matches between sample_A and sample_B.
Please look at the API reference of down_sample() for more
details.
Note
Currently, the input tables must be loaded in memory before the user can down sample.
Profiling Data¶
Profiling data is used to help users get general information about their data. Before working with the data, it is useful for a user to have a high level understanding of the data because he or she will be able to take advantage of the the general trends to successfully and efficiently complete the rest of the workflow.
Data profiling specifically can show users important statistics such as type, uniqueness, missing values, quartile statistics, mean, mode, standard deviation, sum, median absolute deviation, coefficient of variation, kurtosis, skewness. It can also display information to the user visually such as in a histogram.
We recommend using the python package pandas-profiling because it is simple and easy to use. More information about the package can be found on the github page at https://github.com/JosPolfliet/pandas-profiling
Example Usage¶
After reading in a CSV file into a Dataframe, pandas-profiling shows the user a report containing useful profiling information. For example:
>>> import pandas_profiling
>>> # Read in csv file
>>> A = em.read_csv_metadata('path_to_csv_dir/table.csv', key='ID')
>>> # Use the profiler
>>> pandas_profiling.ProfileReport(A)
The user can also check to see if any variables are highly correlated:
>>> # Read in csv file
>>> import pandas_profiling
>>> A = em.read_csv_metadata('path_to_csv_dir/table.csv', key='ID')
>>> #Use the profiler
>>> profile = pandas_profiling.ProfileReport(A)
>>> # Check for rejected variables
>>> rejected_variables = profile.get_rejected_variables(threshold=0.9)
The report generated can also be saved into an html file:
>>> import pandas_profiling
>>> A = em.read_csv_metadata('path_to_csv_dir/table.csv', key='ID')
>>> # Save report to a variable
>>> profile = pandas_profiling.ProfileReport(A)
>>> # Save report to an html file
>>> profile.to_file(outputfile="/tmp/myoutputfile.html")
For more information about pandas-profiling please go to the github page at https://github.com/JosPolfliet/pandas-profiling
Data Exploration¶
Data exploration is an important part of the entity matching workflow because it gives the user a chance to look at the actual data closely. Data exploration allows the user to inspect the individual records and features present in the table so that he or she can understand the important trends and relationships present in the data. A complete understanding of the data gives the user an advantage later on in the entity matching workflow.
OpenRefine¶
OpenRefine is a data exploration tool that is compatible with Python >= 2.7 or Python >= 3.4. More information about OpenRefine can be found at its github page at https://github.com/OpenRefine/OpenRefine
Note
OpenRefine is not included with py_entitymatching and must be downloaded and installed separately. The installation instructions can be found at https://github.com/OpenRefine/OpenRefine/wiki/Installation-Instructions
Using OpenRefine¶
Before using OpenRefine, you must start the application to start an OpenRefine server. The explanations for doing so are explained after the installation instructions at https://github.com/OpenRefine/OpenRefine/wiki/Installation-Instructions
Once the application has created a server, copy the URL from the address bar of the OpenRefine browser (default is http://127.0.0.1:3333 ). Then the data can be explored as in the example below:
>>> import py_entitymatching as em
>>> A = em.read_csv_metadata('path_to_csv_dir/table.csv', key='ID')
>>> p = em.data_explore_openrefine(A, name='Table')
>>> # Save the project back to our dataframe
>>> # Calling export_pandas_frame will automatically delete the OpenRefine project
>>> df = p.export_pandas_frame()
Pandastable¶
Pandastable is a data exploration tool available for python >=3.4 that allows users to view and manipulate data. More information about pandastable can be found at https://github.com/dmnfarrell/pandastable
Note
pandastable is not packaged along with py_entitymatching. You can install pandastable using pip as show below:
$ pip install pandastable
or conda as shown below:
$ conda install -c dmnfarrell pandastable=0.7.1
Using pandastable¶
Pandastable can be easily be used with the wrappers included with py_entitymatching. The following example shows how:
>>> # import py_entitymatching
>>> import py_entitymatching as em
>>> # Explore the data using pandastable
>>> A = em.read_csv_metadata('path_to_csv_dir/table.csv', key='ID')
>>> em.data_explore_pandastable(A)
Specifying Blockers and Performing Blocking¶
In this section, we discuss how you can specify blockers and perform blocking.
Types of Blockers and Blocker Hierarchy¶
Once the tables are loaded and downsampled, most often you have to do blocking. Note that by blocking we mean to block a tuple pair from going through to the matching step. When applied to a tuple pair, a blocker returns True if the pair should be blocked. You must know conceptually the types of blockers and the blocker hierarchy in py_entitymatching to extend or modify them based on your need.
There are two types of blockers: (1) tuple-level, and (2) global. A tuple-level blocker can examine a tuple pair in isolation and decide if it should be admitted to the next stage. For example, an attribute equivalence blocker is a tuple-level blocker. A global blocker cannot make this decision in isolation. It would need to examine a set of other pairs as well. For example, a sorted neighborhood blocker applied over an union of the input tables is a global blocker. Currently, py_entitymatching supports only tuple-level blockers.
The blockers can be combined in complex ways, such as
apply blocker b1 to the two tables
apply blocker b2 to the two tables
apply blocker b3 to the output of b1
Further, you may just want to apply a blocker to just a pair of tuples, to see how the blocker works.
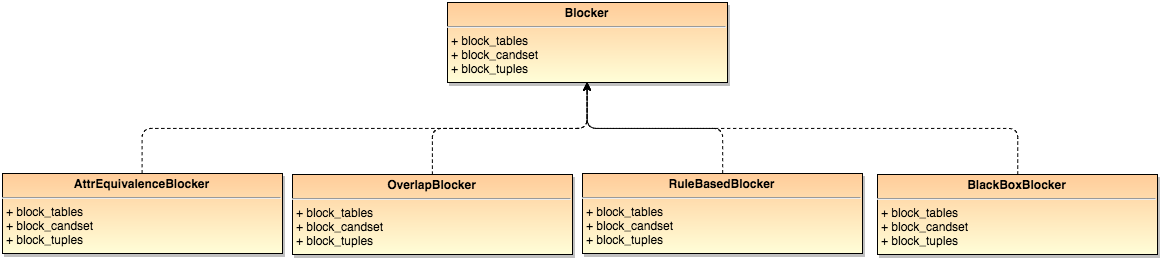
In py_entitymatching, there is a Blocker class from which a set of concrete blockers are inherited. These concrete blockers implement the following methods:
block_tables (apply to input tables A and B)
block_candset (apply to an output from another blocker (e.g. table C))
block_tuples (apply to a tuple pair to check if it will survive blocking)
In py_entitymatching, there are four concrete blockers implemented: (1) attribute equivalence blocker, (2) overlap blocker, (3) rule-based blocker, and (4) black box blocker. All the functions implemented in the concrete blockers are metadata aware.
The class diagram of Blocker and the concrete blockers inherited from it is shown below:
Built-In Blockers¶
Built-in blockers are those that have been built into py_entitymatching and you can just simply call them. py_entitymatching currently offers three built-in blockers.
Attribute Equivalence Blocker
Given two tables A and B, conceptually, block_tables in attribute equivalence blocker takes an attribute x of table A, an attribute y of table B, and returns True (that is, drop the tuple pair) if x and y are not of the same value.
An example of using the above function is shown below:
>>> import py_entitymatching as em
>>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID')
>>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID')
>>> ab = em.AttrEquivalenceBlocker()
>>> C = ab.block_tables(A, B, 'zipcode', 'zipcode', l_output_attrs=['name'], r_output_attrs=['name'])
Please look at the API reference of block_tables()
for more details.
The function block_candset is similar to block_tables except block_candset is applied to the candidate set, i.e. the output from block_tables. An example of using block_candset is shown below:
>>> D = ab.block_candset(C, 'age', 'age')
Please look at the API reference of block_candset()
for more details.
The function block_tuples is used to check if a tuple pair would get blocked. An example of using block_tuples is shown below:
>>> status = ab.block_tuples(A.ix[0], B.ix[0], 'age', 'age')
>>> status
True
Please look at the API reference of block_tuples()
for more details.
Overlap Blocker
Given two tables A and B, conceptually, block_tables in overlap blocker takes an attribute x of table A, an attribute y of table B, and returns True (that is, drop the tuple pair) if x and y do not share any token (where the token is a word or a q-gram).
As part of the pre-processing for this blocker, the strings are first converted to lowercase.
An example of using block_tables is shown below:
>>> import py_entitymatching as em
>>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID')
>>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID')
>>> ob = em.OverlapBlocker()
>>> C = ob.block_tables(A, B, 'zipcode', 'zipcode', overlap_size=1, l_output_attrs=['name'], r_output_attrs=['name'] )
Please look at the API reference of block_tables()
for more details.
The function block_candset is similar to block_tables except block_candset is applied to the candidate set, i.e. the output from block_tables.
An example of using block_candset is shown below:
>>> D = ob.block_candset(C, 'age', 'age')
Please look at the API reference of block_candset()
for more details.
The function block_tuples is used to check if a tuple pair would get blocked. An example of using block_tuples is shown below:
>>> status = ob.block_tuples(A.ix[0], B.ix[0], 'name', 'name', overlap_size=1)
>>> status
True
Please look at the API reference of block_tuples()
for more details.
Sorted Neighborhood Blocker
WARNING: THIS IS AN EXPERIMENTAL COMMAND. THIS COMMAND IS NOT TESTED. USE AT YOUR OWN RISK.
Given two tables A and B, conceptually, block_tables works in the following manner. First, for table A, block_tables creates a blocking attribute for every tuple using the output of l_block_attr. Next, for table B, block_tables similarly creates a blocking attribute using the output of r_block_attr. Then, tables A and B are combined and sorted on the blocking attribute.
Finally, a sliding window of size window_size is passed through the sorted dataset. If two tuples are within window_size positions of each other in sorted order, and the two tuples come from different tables, then the two tuples are returned in the candidate set.
An example of using block_tables is shown below:
>>> import py_entitymatching as em
>>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID')
>>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID')
>>> sn = em.SortedNeighborhoodBlocker()
>>> C = sn.block_tables(A, B, l_block_attr='zipcode', r_block_attr='zipcode', l_output_attrs=['name'], r_output_attrs=['name'], window_size=3 )
Please look at the API reference of block_tables()
for more details.
Unlike the other two blockers, since the sorted neighborhood blocker requires the sorted order of all tuples in the database, block_candset and block_tuples are not applicable and will raise an assertion if called.
Two things to note. First, consider the trade-off of possible values to window_size. If the size is too small, actually-matching tuples will not be returned in the candidate set (and thus, missed). If the window size is very large, the resulting candidate set will also be excessively large, hurting performance. The exact size needed is unique to each dataset.
Second, if window_size is smaller than a range of matching tuples, and actually-matching tuples will be missed, not be returned in the candidate set. However, if the blocking attribute is not sufficient to make a unique sorted order, than the resulting sorted order is one of a set of potential sorted orders. If the method of sorting changes, for instance if more cores are used, a different sorted order may be returned. This sorted order may result in a different candidate set being returned. To avoid this situation it is recommended to add some uniqueness into the blocking attribute (such as the ID), so that there is only one correct sorted order. This will help ensure the same set of results are returned from the same inputs. An example of this is:
>>> A["birth_year_plus_id"]=A["birth_year"].map(str)+'-'+A["ID"].map(str)
>>> B["birth_year_plus_id"]=B["birth_year"].map(str)+'-'+A["ID"].map(str)
>>> C3 = sn.block_tables(A, B, l_block_attr='birth_year_plus_id', r_block_attr='birth_year_plus_id', l_output_attrs=['name', 'birth_year_plus_id', 'birth_year', 'zipcode'], r_output_attrs=['name', 'birth_year_plus_id', 'birth_year', 'zipcode'], l_output_prefix='l_', r_output_prefix='r_', window_size=5)
In this example a new attribute birth_year_plus_id is used as the blocking attribute, and will always have the same sorted order.
Blackbox Blockers¶
By blackbox blockers we mean that the user supplies a Python function which encodes blocking for a tuple pair. Specifically, the Python function will take in two tuples and returns True if the tuple pair needs to be blocked, else returns False. To use a blackbox blocker, first you must write a blackbox blocker function.
An example of blackbox blocker function is shown below:
def match_last_name(ltuple, rtuple):
# assume that there is a 'name' attribute in the input tables
# and each value in it has two words
l_last_name = ltuple['name'].split()[1]
r_last_name = rtuple['name'].split()[1]
if l_last_name != r_last_name:
return True
else:
return False
Then instantiate a blackbox blocker and set the blocking function function as follows:
>>> import py_entitymatching as em
>>> bb = em.BlackBoxBlocker()
>>> bb.set_black_box_function(match_last_name)
Now, you can call block_tables on the input tables. Conceptually, block_tables would apply the blackbox blocker function on the Cartesian product of the input tables A and B, and return a candidate set of tuple pairs.
An example of using block_tables is shown below:
>>> C = bb.block_tables(A, B, l_output_attrs=['name'], r_output_attrs=['name'] )
Please look at the API reference of block_tables()
for more details.
The function block_candset is similar to block_tables except block_candset is applied to the candidate set, i.e. the output from block_tables.
An example of using block_candset is shown below:
>>> D = bb.block_candset(C)
Please look at the API reference of block_candset()
for more details.
Further, block_tuples is used to check if a tuple pair would get blocked. An example of using block_tuples is shown below:
>>> status = bb.block_tuples(A.ix[0], B.ix[0])
>>> status
True
Please look at the API reference of block_tuples()
for more details.
Rule-Based Blockers¶
You can write a few domain specific rules (for blocking purposes) using rule-based blocker. If you want to write rules, then you must start by defining a set of features. Each feature is a function that when applied to a tuple pair will return a numeric value. We will discuss how to create a set of features in the section Creating Features for Blocking.
Once the features are created, py_entitymatching stores this set of features in a feature table. We refer to this feature table as block_f. Then you will be able to instantiate a rule-based blocker and add rules like this:
>>> rb = em.RuleBasedBlocker()
>>> rb.add_rule(rule1, block_f)
>>> rb.add_rule(rule2, block_f)
In the above, block_f is a set of features stored as a Dataframe (see section Creating Features for Blocking).
Each rule is a list of strings. Each string specifies a conjunction of predicates. Each predicate has three parts: (1) an expression, (2) a comparison operator, and (3) a value. The expression is evaluated over a tuple pair, producing a numeric value. Currently, in py_entitymatching an expression is limited to contain a single feature (being applied to a tuple pair). So an example predicate will look like this:
name_name_lev(ltuple, rtuple) > 3
In the above name_name_lev is feature. Concretely, this feature computes Levenshtein distance between the name values in the input tuple pair.
As an example, the rules rule1 and rule2 can look like this:
rule1 = ['name_name_lev(ltuple, rtuple) > 3', 'age_age_exact_match(ltuple, rtuple) !=0']
rule2 = ['address_address_lev(ltuple, rtuple) > 6']
In the above, rule1 contains two predicates and rule2 contains just a single predicate. Each rule is a conjunction of predicates. That is, each rule will return True only if all the predicates return True. The blocker is then a disjunction of rules. That is, even if one of the rules return True, then the tuple pair will be blocked.
Once the rules are specified, you can call block_tables on the input tables. Conceptually, block_tables would apply the rule-based blocker function on the Cartesian product of the input tables A and B and return a candidate set of tuple pairs.
An example of using block_tables is shown below:
>>> C = rb.block_tables(A, B, l_output_attrs=['name'], r_output_attrs=['name'] )
Please look at the API reference of block_tables()
for more details.
The function block_candset is similar to block_tables except block_candset is applied to the candidate set, i.e. the output from block_tables.
An example of using block_candset is shown below:
>>> D = rb.block_candset(C)
Please look at the API reference of block_candset()
for more details.
The function block_tuples is used to check if a tuple pair would get blocked. An example of using block_tuples is shown below:
>>> status = rb.block_tuples(A.ix[0], B.ix[0])
>>> status
True
Please look at the API reference of block_tuples()
for more details.
Combining Multiple Blockers¶
If you use multiple blockers, then you have to combine them to get a consolidated candidate set. There are many different ways to combine the candidate sets such as doing union, majority vote, weighted vote, etc. Currently, py_entitymatching only supports union-based combining.
In py_entitymatching, combine_blocker_outputs_via_union is used to do union-based combining.
An example of using combine_blocker_outputs_via_union is shown below:
>>> import py_entitymatching as em
>>> ab = em.AttrEquivalenceBlocker()
>>> C = ab.block_tables(A, B, 'zipcode', 'zipcode')
>>> ob = em.OverlapBlocker()
>>> D = ob.block_candset(C, 'address', 'address', overlap_size=1)
>>> block_f = em.get_features_for_blocking(A, B)
>>> rb = em.RuleBasedBlocker()
>>> rule = ['name_name_lev(ltuple, rtuple) > 6']
>>> rb.add_rule(rule, block_f)
>>> E = rb.block_tables(A, B)
>>> F = em.combine_blocker_outputs_via_union([C, E])
Conceptually, the command takes in a list of blocker outputs (i.e. pandas Dataframes) and produces a consolidated table. The output table contains the union of tuple pair ids and other attributes from the input list.
Please look at the API reference of combine_blocker_outputs_via_union()
for more details.
Creating Features for Blocking¶
Recall that when doing blocking, you can use built-in blockers, blackbox blockers, or rule-based blockers. For rule-based blockers, you have to create a set of features. While creating features, you will have to refer to tokenizers, similarity functions, and attributes of the tables. Currently, in py_entitymatching, there are two ways to create features:
Automatically generate a set of features (then you can remove or add some more).
Skip the automatic process and generate features manually.
Note that features will also be used in the matching process, as we will discuss later.
If you are interested in just letting the system to automatically generate a set of features, then please see Generating Features Automatically.
If you want to generate features on your own, please read below.
Available Tokenizers and Similarity Functions¶
A tokenizer is a function that takes a string and optionally a number of other arguments, then tokenizes the string and returns a set of tokens. Currently, the following tokenizers are provided along with py_entitytmatching:
Alphabetic
Alphanumeric
White space
Delimiter based
Qgram based
A similarity function takes two arguments (can be strings, numeric values, etc.), which are typically two attribute values such as two book titles, then returns an output value which is typically a similarity score between the two attribute values. Currently, the following similarity functions are provided along with py_entitytmatching:
Affine
Hamming distance
Jaro
Jaro-Winkler
Levenshtein
Monge-Elkan
Needleman-Wunsch
Smith-Waterman
Jaccard
Cosine
Dice
Overlap coefficient
Exact match
Absolute norm
Obtaining Tokenizers and Similarity Functions¶
First you need to get tokenizers and similarity functions to refer them in features. In py_entitymatching, you can use get_tokenizers_for_blocking to get all the tokenizers available for blocking purposes.
>>> block_t = em.get_tokenizers_for_blocking()
In the above, block_t is a dictionary where keys are tokenizer names and values are tokenizer functions in Python. You can inspect block_t and delete/add tokenizers as appropriate. The above command will return single-argument tokenizers, i.e., those that take a string then produce a set of tokens.
Each of the keys of the default dictionary returned to ‘block_t’ by ‘get_tokenizers_for_blocking’ represent a tokenizer that can be used by similarity functions. The keys and the respective tokenizer they represent are shown below:
alphabetic: Alphabetic tokenizer
alphanumeric: Alphanumeric tokenizer
dlm_dc0: Delimiter tokenizer using spaces as the delimiter
qgm_2: Two Gram tokenizer
qgm_3: Three Gram tokenizer
wspace: Whitespace tokenizer
Please look at the API reference of get_tokenizers_for_blocking()
for more details.
Similarly, the user can use get_sim_funs_for_blocking to get all the similarity functions available for blocking purposes.
>>> block_s = em.get_sim_funs_for_blocking()
In the above, block_s is a dictionary where keys are similarity function names and values are similarity functions in Python. Similar to block_t, you can inspect block_s and delete/add similarity functions as appropriate.
Each of the keys of the default dictionary returned to ‘block_s’ by ‘get_sim_funs_for_blocking’ represent a similarity function. The keys and the respective similarity function they represent are shown below:
abs_norm: Absolute Norm
affine: Affine Transformation
cosine: Cosine Similarity
dice: Dice similarity Coefficient
exact_match: Exact Match
hamming_dist: Hamming Distance
hamming_sim: Hamming Similarity
jaccard: Jaccard Similarity
jaro: Jaro Distance
jaro_winkler: Jaro-Winkler Distance
lev_dist: Levenshtein Distance
lev_sim: Levenshtein Similarity
monge_elkan: Monge-Elkan Algorithm
needleman_wunsch: Needleman-Wunsch Algorithm
overlap_coeff: Overlap Coefficient
rel_diff: Relative Difference
smith_waterman: Smith-Waterman Algorithm
Please look at the API reference of get_sim_funs_for_blocking()
for more details.
Obtaining Attribute Types and Correspondences¶
In the next step, you need to obtain type and correspondence information about A and B so that the features can be generated.
First, you need to obtain the types of attributes in A and B, so that the right tokenizers/similarity functions can be applied to each of them. In py_entitymatching, you can use get_attr_types to get the attribute types. An example of using get_attr_types is shown below:
>>> atypes1 = em.get_attr_types(A)
>>> atypes2 = em.get_attr_types(B)
In the above, atypes1 and atypes2 are dictionaries. They contain, the type of
attribute in each of the tables. Note that this type is different from basic
Python types. Please look at the API reference of
get_attr_types() for more details.
Next, we need to obtain correspondences between the attributes of A and B, so that the features can be generated based on those correspondences. In py_entitymatching, you can use get_attr_corres to get the attribute correspondences.
An example of using get_attr_corres is shown below:
>>> block_c = em.get_attr_corres(A, B)
In the above, block_c is a dictionary containing attribute correspondences.
Currently, py_entitymatching returns attribute correspondences only based on the exact
match of attribute names. You can inspect block_c and modify the attribute
correspondences. Please look at the API reference of
get_attr_corres() for more details.
Getting a Set of Features¶
Recall that so far we have obtained:
block_t, the set of tokenizers,
block_s, the set of sim functions
atypes1 and atypes2, the types of attributes in A and B
block_c, the correspondences of attributes in A and B
Next, to obtain a set of features, you can use get_features command. An example of using get_features command is shown below:
>>> block_f = em.get_features(A, B, atypes1, atypes2, block_c, block_t, block_s)
Briefly, this function will go through the correspondences. For each
correspondence m, it examines the types of the involved attributes,
then apply the appropriate tokenizers and similarity functions to generate
all appropriate features for this correspondence. The features are returned as
a Dataframe. Please look at the API reference of
get_features() for more details.
Adding/Removing Features¶
Given the set of features block_f as a pandas Dataframe, you can delete certain features, add new features.
Deletion of a feature is straightforward, all that you have to do is delete the row from the feature table corresponding to the feature. You can use drop command from pandas Dataframe for this purpose. Please look at this API reference link for more details.
There are two ways to create and add a feature: (1) write a blackbox function and add it to feature table, and (2) define a feature declartively and add it to feature table.
Adding a Blackbox Function as Feature
To create and add a blackbox function as a feature, first you must define it. Specifically, the function must take in two tuples as input and return a numeric value. An example of a blackbox function is shown below:
def age_diff(ltuple, rtuple):
# assume that the tuples have age attribute and values are valid numbers.
return ltuple['age'] - rtuple['age']
Then add it to the feature table block_f using add_blackbox_feature like this:
>>> status = em.add_blackbox_feature(block_f, 'age_difference', age_diff)
Please look at the API reference of
add_blackbox_feature() for more details.
Adding a Feature Declaratively
Another way to add features is to write a feature expression in a declarative way. py_entitymatching will then compile it into a feature. For example, you can declaratively create and add a feature like this:
>>> r = em.get_feature_fn('jaccard(qgm_3(ltuple["name"]), qgm_3(rtuple["name"]))', block_t, block_s)
>>> em.add_feature(block_f, 'name_name_jac_qgm3_qgm3', r)
Here block_t and block_s refer to the dictionaries containing a set of tokenizers and similarity functions for blocking. Additionally, ‘jaccard’ refers to the key in ‘block_s’ that represents the Jaccard Similarity function and ‘qgm_3’ refers to the key in ‘block_t’ that represents a three gram tokenizer. The keys in ‘block_t’ and ‘block_s’ and which function or tokenizer they represent are explained above in the Obtaining Tokenizers and Similarity Functions section.
Conceptually, the first command, get_feature_fn, creates a feature which is a Python function that will take two tuples ltuple and rtuple, get the attribute publisher from ltuple, issuer from rtuple, tokenize them, then compute jaccard score.
Note
The feature must refer the tuple from the left table (say A) as ltuple and the tuple from the right table (say B) as rtuple.
The second command, add_feature tags the feature with the specified name, and adds it to the feature table.
As described, the feature that was just created is independent of any table (eg A and B). Instead, it expects as the input two tuples: ltuple and rtuple.
You can also create more complex features. Specifically, you are allowed to define arbitrary complex expression involving function names from block_t and block_s, and attribute names from ltuple and rtuple.
>>> r = em.get_feature_fn('jaccard(qgm_3(ltuple.address + ltuple.zipcode), qgm_3(rtuple.address + rtuple.zipcode)',block_t,block_s)
>>> em.add_feature(block_f, 'full_address_address_jac_qgm3_qgm3', r)
You can also create your own similarity functions and tokenizers for your custom features. For example, you can create a similarity function that changes all strings to lowercase before checking if they are equivalent.
>>> # This similarity function converts the two strings to lowercase before checking if they are an exact match
>>> def match_lowercase(l_attr, r_attr):
>>> l_attr = l_attr.lower()
>>> r_attr = r_attr.lower()
>>> if l_attr == r_attr:
>>> return 1
>>> else:
>>> return 0
You can then add a feature declarativly with your new similarity function.
>>> # The new similarity function is added to block_s and then a new feature is created
>>> block_t = em.get_tokenizers_for_blocking()
>>> block_s = em.get_sim_funs_for_blocking()
>>> block_s['match_lowercase'] = match_lowercase
>>> r = em.get_feature_fn('match_lowercase(ltuple["name"], rtuple["name"])', block_t, block_s)
>>> em.add_feature(block_f, 'name_name_match_lowercase', r)
It is also possible to create features with your own similarity functions that require tokenizers. The next example shows how to create a custom tokenizer that returns only the first and last words of a string.
>>> # This custom tokenizer returns the first and last words of a string
>>> def first_last_tok(attr):
>>> all_toks = attr.split(" ")
>>> toks = [all_toks[0], all_toks[len(all_toks) - 1]]
>>> return toks
Next, a similarity function that can utilize the new tokenizer is created. This example shows how to create a similarity function that raises the score if the first words match and raises the score by one if the second words match.
>>> # This similarity function compares two tokens from each set.
>>> # Greater weight is placed on the equality of the first token.
>>> def first_last_sim(l_attr, r_attr):
>>> score = 0
>>> if l_attr[0] == r_attr[0]:
>>> score += 2
>>> if l_attr[1] == r_attr[1]:
>>> score +=1
>>> return score
Finally, with the tokenizer and similarity functions defined, the new feature can be created and added.
>>> # The new tokenizer is added to block_t and the new similarity function is added to block_s
>>> # then a new feature is created
>>> block_t = em.get_tokenizers_for_blocking()
>>> block_t['first_last_tok'] = first_last_tok
>>> block_s = em.get_sim_funs_for_blocking()
>>> block_s['first_last_sim'] = first_last_sim
>>> r = em.get_feature_fn('first_last_sim(first_last_tok(ltuple["name"]), first_last_tok(rtuple["name"]))',
>>> block_t, block_s)
>>> em.add_feature(block_f, 'name_name_fls_flt_flt', r)
Please look at the API reference of
get_feature_fn() and add_feature()
for more details.
Summary of the Manual Feature Generation Process¶
Here is the summary of commands for the entire manual feature generation process.
To generate features, you must execute the following commands:
>>> block_t = em.get_tokenizers_for_blocking()
>>> block_s = em.get_sim_funs_for_blocking()
>>> atypes1 = em.get_attr_types(A)
>>> atypes2 = em.get_attr_types(B)
>>> block_c = em.get_attr_corres(A, B)
>>> block_f = em.get_features(A, B, atypes1, atypes2, block_c, block_t, block_s)
The variable block_f points to a Dataframe containing features as rows.
Ways to Edit the Manual Feature Generation Process¶
Here is the summary of ways to edit the variables used in feature generation process.
The block_t, block_s, atypes1, atypes2, block_c are dictionaries. You can modify these variables based on your need, to add/remove tokenizers, similarity functions, attribute correspondences, etc.
block_f is a Dataframe. You can remove a feature by just deleting the corresponding tuple from the Dataframe.
There are two ways to create and add a feature: (1) write a blackbox function and add it to feature table, and (2) define the feature declartively and add it to feature table. To add a blackbox feature, first write a blackbox function like this:
def age_diff(ltuple, rtuple): # assume that the tuples have age attribute and values are valid numbers. return ltuple['age'] - rtuple['age']
Then add it to the table block_f using add_blackbox_feature like this:
>>> status = em.add_blackbox_feature(block_f, 'age_difference', age_diff)
To add a feature declaratively, first write a feature expression and compile it to feature using get_feature_fn like this:
>>> r = em.get_feature_fn('jaccard(qgm_3(ltuple.address + ltuple.zipcode), qgm_3(rtuple.address + rtuple.zipcode)',block_t,block_s)
Then add it to the table block_f using add_feature like this:
>>> em.add_feature(block_f, 'full_address_address_jac_qgm3_qgm3', r)
Generating Features Automatically¶
Recall that to get the features for blocking, eventually you must execute the following:
>>> block_f = em.get_features(A, B, atypes1, atypes2, block_c, block_t, block_s)
where atypes1/atypes2 are the attribute types of A and B, block_c is the correspondences between their attributes, block_t is the set of tokenizers, and block_s is the set of similarity functions.
If you don’t want to go through the hassle of creating these intermediate variables, then you can execute the following:
>>> block_f = em.get_features_for_blocking(A,B)
The system will automatically generate a set of features and return it as as a Dataframe which you can then use for blocking purposes. This Dataframe contains a few attributes that require further explanation, specifically ‘left_attr_tokenizer’, ‘right_attr_tokenizer’, and ‘simfunction’. There are two types of similarity functions, those that use tokenizers and those that do not. Some similarity functions use tokenizers and all such features must designate a tokenizer for both the left table attribute in ‘left_attr_tokenizer’ and for the right table attribute in ‘right_attr_tokenizer’. The ‘simfunction’ attribute refers to the name of the function and comes from the keys in ‘block_s’. The various keys and the actual functions they correspond to are explained in the Obtaining Tokenizers and Similarity Functions section above.
The command get_features_for_blocking will set the following variables: _block_t, _block_s, _atypes1, _atypes2, and _block_c. You can access these variables like this:
>>> em._block_t
>>> em._block_s
>>> em._atypes1
>>> em._atypes2
>>> em._block_c
You can examine these variables, modify them as appropriate, and then perhaps re-generate the set of features using get_features command.
Please look at the API reference of
get_features_for_blocking() for more details.
Debugging Blocking¶
In a typical entity matching workflow, you will load in the two tables to match, sample them (if required) and use a blocker to remove obvious non-matches. But it is often not clear whether the blocker drops only non-matches or it also removes a lot of potential matches.
In such cases, it is important to debug the output of blocker. In py_entitymatching, debug_blocker command can be used for that purpose.
The debug_blocker command takes in two input tables A, B, blocker output C and returns a table D containing a set of tuple pairs that are potential matches and yet are not present in the blocker output C. Table D also contains similarity measure computed for each reported tuple pair (as its second column).
You can examine these potential matches in table D. If you find that many of them are indeed true matches, then that means the blocker may have removed too many true matches. In this case you may want to relax the blocker by modifying its parameters, or choose a different blocker. On the other hand, if you do not find many true matches in table D, then it could be the case that the blocker has done a good job and preserve all the matches (or most of the matches) in the blocker output C.
In the debug_blocker, you can optionally specify attribute correspondences between the input tables A and B. If it is not specified, then attribute correspondences will be a list of attribute pairs with the exact same names in A and B.
The debugger will use only the attributes mentioned in these attribute correspondences to try to find potentially matching pairs and place those pairs into D. Thus, our recommendation is that (a) if the tables have idential schemas or share a lot of attributes with the same names, then do not specify the attribute correspondences, in this case the debugger will use all the attributes with the same name between the two schemas, (b) otherwise think about what attribute pairs you want to see the debugger use, then specify those as attribute correspondences.
An example of using debug_blocker is shown below:
>>> import py_entitymatching as em
>>> ob = em.OverlapBlocker()
>>> C = ob.block_tables(A, B, l_overlap_attr='title', r_overlap_attr='title', overlap_size=3)
>>> corres = [('ID','ssn'), ('name', 'ename'), ('address', 'location'),('zipcode', 'zipcode')]
>>> D = em.debug_blocker(C, A, B, attr_corres=corres)
Please refer to the API reference of debug_blocker()
for more details.
The blocker debugger is implemented in Cython. In case this version of the
command is not working properly, there is also a python version of the command,
called backup_debug_blocker, available that can be used instead. Please refer
to the API reference of backup_debug_blocker() for
more details.
Sampling¶
If you have to use supervised learning-based matchers or evaluate matchers, you need to create labeled data. To create labeled data, first you need to sample of candidate set pairs and then label them.
In py_stringmatching, you can use sample_table to get a sample. The command does uniform random sampling without replacement. An example of using sample_table is shown below:
>>> S = em.sample_table(C, 100)
The command will first create a copy of the input table, sample the specified number of tuple pairs from the copy, update the metadata and return the sampled table.
For more details, please look into the API reference of sample_table()
Labeling¶
The command label_table can be used to label the samples (see section Sampling). An example of using label_table is shown below:
>>> G = em.label_table(S, label_column_name='gold_labels')
The above command will first create a copy of the input table S, update the metadata, add a column with the specified column name (in label_col_name parameter) fill it with 0 (i.e non-matches) and open a GUI for you to update the labels. You must specify 0 for non-matches and 1 for matches. Once you close the GUI, the updated table will be returned.
Please refer to the API reference of label_table()
for more details.
Splitting Labeled Data into Training and Testing Sets¶
While doing entity matching you will have to split data for multiple purposes. Some examples are:
1. Split labeled data into development and test. Th development set is used to come up with right features for learning-based matcher, and test set is used to evaluate the matcher.
2. Split feature vectors into a train and test set. The train set is used to train the learning-based matcher and test set is used for evaluation.
py_entitymatching provides split_train_test command for the above need. An example of using split_train_test is shown below:
>>> train_test = em.split_train_test(G, train_proportion=0.5)
In the above, split_train_test returns a dictionary with two keys: train, and test. The value for the key train is a Dataframe containing tuples allocated from the input table based on train_proportion. Similarly, the value for the key test is a Dataframe containing tuples for evaluation. An example of getting train and test Dataframes from the output of split_train_test command is shown below:
>>> devel_set = train_test['train']
>>> eval_set = train_test['test']
Setting the value for train proportion would depend on the context of its use. For instance, if the data is split for machine learning purposes then train proportion is typically larger than the test. The most commonly used values of train_proportion are between 0.5 and 0.8.
Please refer to the API reference of split_train_test() for
more details.
Creating Features for Matching¶
If you have to use supervised learning-based matchers, then you cannot just operate on the labeled set of tuple pairs. For each tuple in the labeled, you need to convert it into a feature vector which consists of a list of numerical/categorical features. To do this, first we need to create a set of features.
There are two ways to create features:
Automatically create a set of features (then the user can remove or add some more).
Skip the automatic process and generate features manually.
Creating the Features Manually¶
This is very similar to manual feature creation process for blocking (see section Creating Features for Blocking) except the features are created for matching purposes. In brief, you can execute the following sequence of commands in py_entitymatching to create the features manually:
>>> match_t = em.get_tokenizers_for_matching()
>>> match_s = em.get_sim_funs_for_matching()
>>> atypes1 = em.get_attr_types(A) # don't need, if atypes1 exists from blocking step
>>> atypes2 = em.get_attr_types(B) # don't need, if atypes2 exists from blocking step
>>> match_c = em.get_attr_corres(A, B)
>>> match_f = em.get_features(A, B, atypes1, atype2, match_c, match_t, match_s)
Further, you can add or delete features as see saw in section Adding/Removing Features.
Please refer to the API reference of get_tokenizers_for_matching()
and py_entitymatching.get_sim_funs_for_matching() for more details.
Note
Currently, py_entitymatching returns the same set of features for blocking and matching purposes.
Creating the Features Automatically¶
If you do not want to go through the hassle of creating the features manually, then the user can generate the features automatically. This is very similar to automatic feature creation process for blocking (see section Generating Features Automatically).
In py_entitymatching, you can use get_features_for_matching to generate features for matching purposes automatically. An example of using get_features_for_matching is shown below:
>>> match_f = em.get_features_for_matching(A, B)
Similar to what we saw in section Generating Features Automatically for blocking, the command will set the following variables: _match_t, _match_s, _atypes1, _atypes2, _match_c and they can be accessed like this:
>>> em._match_t
>>> em._match_s
>>> em._atypes1
>>> em._atypes2
>>> em._match_c
You can to examine these variables, modify them as appropriate, and then
perhaps regenerate a set of features.
Please refer to the API reference of get_features_for_matching()
for more details.
Extracting Feature Vectors¶
Once you have created a set of features, you use them to convert labeled sample to feature vectors. In py_entitymatching, you can use extract_feature_vecs to convert labeled sample to feature vectors using the features created (see section Creating Features for Matching).
An example of using extract_feature_vecs is shown below:
>>> H = em.extract_feature_vecs(G, feature_table=match_f, attrs_before=['title'], attrs_after=['gold_labels'])
Conceptually, the command takes the labeled data (G), applies the feature functions (in match_f) to each tuple in G to create a Dataframe, adds the attrs_before and attrs_after columns, updates the metadata and returns the resulting Dataframe.
If there is one (or several columns) in labeled data that contains the labels, then those need to be explicitly specified in attrs_after, if you want them them to copy over.
Please refer to the API reference of extract_feature_vecs()
for more details.
Imputing Missing Values¶
While doing supoervised learning-based matching, you would need to create labeled sample, convert the sample into table of feature vectors, fill in the missing values, select a machine learning (ML) model and use it to produce matches.
The step of filling in the missing values (also called imputing missing values) is important and necessary. If there are missing values in the input tables A and B, then they would be passed on to candidate set and most likely to the feature vectors. In py_entitymatching, if the feature vectors contain missing values, then most of the ML algorithms would not work as they rely on scikit-learn package to provide ML-algorithm implementations (and their implementations would not work if the feature vectors contain NaN’s).
To avoid missing value problem in the feature vectors, you must impute the values of the NaN’s. There are many different ways to impute missing values such as filling the NaN’s (in the whole table or just some columns) with a constant value, or fill the NaN’s with an aggregate value (mean, median, etc.).
Since the table is represented as a pandas Dataframe, there are two common ways to impute missing values: (1) use fillna method from pandas Dataframe, and (2) impute missing values using Imputer from Scikit-learn package.
But there are two problems that we have to tackle if we have to using the above commands or objects directly:
They are not metadata aware, so the user has to explicitly take care of it.
The Dataframe type that gets imputed typically contains attributes such as key, foreign keys to A and B. The user must have to rightly project them out to impute missing values using aggregates.
In py_entitymatching, we propose a hybrid method to impute missing values. To fill NaN’s with a constant value use fillna command from pandas Dataframe. Please look at the API reference of fillna for more details. An example of using fillna to the whole table is shown below:
>>> H.fillna(value=0, inplace=True)
In the above, H is a Dataframe containing feature vectors, 0 is the constant value that to be filled in, and inplace=True means that the updation should be done in place (i.e., without creating a copy). It is important to set inplace=True as we do not want the metadata for H in Catalog to be corrupted.
Another example of using fillna on a column is shown below:
>>> H['name_name_lev'] = H['name_name_lev'].fillna(value=0, inplace=False)
Note that, in the above inplace should be specified as False, this is because the output is getting assigned to a column in the old Dataframe H and the metadata of H does not get affected.
To fill NaN’s with an aggregate value, in py_entitymatching you can use impute_table command. It is a wrapper around scikit-learn’s Imputer object (to make it metadata aware). An example of using impute_table is shown below:
>>> H = em.impute_table(H, exclude_attrs=['_id', 'ltable_id', 'rtable_id'], strategy='mean')
Note
If all the values in a column or a row are NaN’s, then the above aggregation strategy will not work (i.e. we cannot compute the mean and use it to fill the missing values). In such cases, you need to specify a value in val_all_nans parameter and the command will use this value to fill in all the missing values.
Please refer to the API reference of impute_table() for
more details.
Specifying Matchers and Performing Matching¶
ML-Matchers¶
Once yor convert the labeled sample into a table of feature vectors (and their labels), the we can can create and apply matchers to the feature vectors. Currently py_entitymatching supports only ML-based matchers. Implementation wise, a Matcher is defined as a Python class with certain methods (and some common utility functions) and all concrete blockers inherit from this Matcher class and override the methods. Specifically, each concrete matcher will implement at least the following methods:
fit (for training)
predict (for prediction)
Creating Learning-Based Matchers¶
In py_entitymatching, there are seven concrete ML-matchers implemented: (1) naive bayes, (2) logistic regression, (3) linear regression, (4) support vector machine, (5) decision trees, (6) random forest, and (7) xgboost matcher.
These concrete matchers are just wrappers of scikit-learn matchers or that supports scikit-learn wrappers (for eg., xgboost) and this is because the fit/predict methods in scikit-learn are not metadata aware. The concrete matchers make the scikit-learn matchers metadata aware.
Each matcher can be created by calling its constructor. Since these matchers are just the wrappers of scikit-learn matchers, the parameters that can be given to scikit-learn matchers can be to given to the matchers in py_entitymatching. For example, a user can create a Decision Tree matcher like this:
>>> dt = em.DTMatcher(max_depth=5)
Please refer to DTMatcher(), RFMatcher(),
NBMatcher(), LogisticRegressionMatcher(),
LinearRegressionMatcher(), SVMMatcher(), and
XGBoostMatcher()
for more details.
Training Learning-Based Matchers¶
Once the ML-matcher is instantiated, you can train the matcher using the fit command. An example of using the fit command for Decision Tree matcher is shown below:
>>> dt.fit(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id'], target_attr='gold_labels')
There are other variants of fit method. As an example, Please refer to
fit() for more details.
Applying Learning-Based Matchers¶
Once the ML-matcher is trained, you can predict the matches using the predict command. An example of using the predict command for Decision Tree matcher is shown below:
>>> dt.predict(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id'], target_attr='predicted_labels', return_probs=True, probs_attr='proba', append=True,
inplace=True)
There are other variants of predict method. As an example, Please refer to
predict() for more details.
Rule-Based Matchers¶
You can write a few domain specific rules (for matching purposes) using the rule-based matcher. If you want to write rules, then you must start by defining a set of features. Each feature is a function that when applied to a tuple pair will return a numeric value. We will discuss how to create a set of features in the section label-create-features-matching.
Once the features are created, py_entitymatching stores this set of features in a feature table. We refer to this feature table as match_f. Then you will be able to instantiate a rule-based matcher and add rules.
Adding and Deleting Rules¶
Once you have created the features for matching, you can create rules like this:
>>> brm = em.BooleanRuleMatcher()
>>> brm.add_rule(rule1, match_f)
>>> brm.add_rule(rule2, match_f)
In the above, match_f is a set of features stored as a Dataframe (see section label-create-features-matching).
Each rule is a list of strings. Each string specifies a conjunction of predicates. Each predicate has three parts: (1) an expression, (2) a comparison operator, and (3) a value. The expression is evaluated over a tuple pair, producing a numeric value. Currently, in py_entitymatching an expression is limited to contain a single feature (being applied to a tuple pair). So an example predicate will look like this:
name_name_lev(ltuple, rtuple) > 3
In the above name_name_lev is feature. Concretely, this feature computes Levenshtein distance between the name values in the input tuple pair.
As an example, the rules rule1 and rule2 can look like this:
rule1 = ['name_name_lev(ltuple, rtuple) > 3', 'age_age_exact_match(ltuple, rtuple) !=0']
rule2 = ['address_address_lev(ltuple, rtuple) > 6']
In the above, rule1 contains two predicates and rule2 contains just a single predicate. Each rule is a conjunction of predicates. That is, each rule will return True only if all the predicates return True. The matcher is then a disjunction of rules. That is, even if one of the rules return True, then the tuple pair will be a match.
Rules can also be deleted once they have been added to the matcher:
>>> rule_name = brm.add_rule(rule_1, match_f)
>>> brm.delete_rule(rule_name)
The command delete_rule must be given the name of the rule to be deleted. Rule names and information on rules in a matcher can be found using the following commands:
>>> # get a list of rule names
>>> rule_names = brm.get_rule_names()
>>> # view rule source
>>> brm.view_rule('rule_name')
>>> # get rule fn
>>> brm.get_rule('rule_name')
Applying Rule-Based Matcher¶
Once the rules are specified, you can predict the matches using the predict command. An example of using the predict command is shown below:
>>> brm.predict(table=H, target_attr='predicted_labels', inplace=True)
For more information on the predict method, please refer to
predict() for more details.
Selecting a ML-Matcher¶
Once you have created different concrete ML matchers, then you have to choose one of them for matching purposes. There are many different criteria by which one can decide to choose a matcher such as akaike information criterion, bayesian information criterion, k-fold cross validation, etc. Currently py_entitymatching supports k-fold cross validation and other approaches are left for future work.
Conceptually, the command to select a matcher would take in the following inputs:
List of ML matchers.
Training data (feature vector).
A column of labels that correspond to the feature vectors in the training data.
Number of folds.
And it would produce the following output:
Selected matcher.
Statistics such as mean accuracy of all input matchers.
In py_entitymatching, select_matcher command addresses the above needs. An example of using select_matcher is shown below:
>>> dt = em.DTMatcher()
>>> rf = em.RFMatcher()
>>> result = em.select_matcher(matchers=[dt, rf], table=train, exclude_attrs=['_id', 'ltable_id', 'rtable_id'], target_attr='gold_labels', k=5)
In the above the output, result is a dictionary containing three keys: (1) selected_matcher, (2) cv_stats, and (3) drill_down_cv_stats. selected_matcher is the selected ML-based matcher, cv_stats is a Dataframe which includes the average cross validation scores for each matcher and for each metric, and ‘drill_down_cv_stats’ is a dictionary where each key is a metric that includes the cross validation statistics for each fold.
Please refer to the API reference of select_matcher() for
more details.
Debugging ML-Matchers¶
While doing entity matching you would like to choose a matcher that produces the desired precision, recall or F1 numbers. If a matcher does not produce the desired accuracy, then you would like to debug the matcher. py_entitymatching supports two ways to debug: (1) using the GUI, and (2) using the command line.
Debugging Using the GUI¶
py_entitymatching supports debugging using the GUI for a subset of ML-based matchers. Specifically, it supports debugging Decision Tree matcher and Random Forest matcher. You can use vis_debug_dt and vis_debug_rf to debug Decision Tree matcher and Random Forest matcher respectively.
An example of using vis_debug_dt is shown below:
>>> dt = em.DTMatcher()
>>> train_test = em.split_train_test(devel, 0.5)
>>> train, test = train_test['train'], train_test['test']
>>> em.vis_debug_dt(dt, train, test, exclude_attrs=['_id', 'ltable_id', 'rtable_id'], target_attr='gold_labels')
The command would display a GUI containing evaluation summary and an option to see tuples flagged as false positives or false negatives. If you select false positives then false positive tuple pairs would be displayed in the adjoining window. Similarly, if false negatives is selected then false negative tuple pairs would be displayed. By default, false positives is selected. Each tuple pair is displayed with two buttons: show and debug. If you click on show, then individual tuples (of that tuple pair) are displayed in a separate window. If you click on debug, then a window with individual tuples and the path taken by the feature vector in the Decision Tree that leads to the predicted value is displayed.
The usage of vis_debug_rf is same as vis_debug_dt. The command would display a GUI similar to vis_debug_dt, except the debug window would list a set of trees. You can expand each tree to see the path taken by the features in that tree.
Please refer to the API reference of vis_debug_dt() and
vis_debug_rf() for more details.
If you want to debug a Decision Tree matcher or Random Forest matcher using GUI, then we recommend the following steps:
In the displayed GUI, check precision and recall numbers in evaluation summary.
If the user wants to improve precision, then he/she should choose to see false positives.
If the user wants to improve recall, then he/she should choose to see false negatives.
In the displayed (false positive/false negative) tuple pairs, you can click on the show button to see the tuples from the left and right tables.
In the displayed (false positive/false negative) tuple pairs, you can choose a tuple and click on the debug button to see the detailed evaluation path of that tuple.
Based on the input tuples, predicates at each node and the actual feature value, you should decide on the next step. Some of the possible next steps are cleaning the input data, adding more features, adding more training data, trying a different matcher, etc.
Debugging Using the Command Line¶
Similar to debugging using the GUI, py_entitymatching supports command line debugging for two ML matchers: Decision Tree and Random Forest. Currently, py_entitymatching supports command line debugging only using tuple pairs, other approaches are left for future work.
You can use debug_decisiontree_matcher and debug_randomforest_matcher to debug Decision Tree matcher and Random Forest matcher respectively.
An example of using debug_decisiontree_matcher is shown below:
>>> H = em.extract_feat_vecs(devel, feat_table=match_f, attrs_after='gold_labels')
>>> dt = em.DTMatcher()
>>> dt.fit(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels')
>>> out = dt.predict(table=F, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels')
>>> em.debug_decisiontree_matcher(dt, A.ix[1], B.ix[2], match_f, H.columns, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels')
In the above, the debug command prints the path taken by the feature vector, its evaluation status at each node and the actual feature value at each node.
The usage of debug_randomforest_matcher is same as debug_decisiontree_matcher. Similar to debug_decisiontree_matcher command, it prints the path taken by the feature vector, except that it displays the path taken in each tree of the Random Forest.
Please refer to the API reference of debug_decisiontree_matcher()
and debug_randomforest_matcher() for more details.
If you want to debug a Decision Tree matcher or Random Forest matcher using the command line, then we recommend the following steps:
Evaluate the accuracy of predictions using user created labels. The evaluation can be done using
eval_matches()command.If you want to improve precision, then he/she should debug false positives.
If you want to improve recall, then he/she should debug false negatives.
You should then retrieve the tuples from the tuple id pairs listed in evaluation summary, and debug using the commands described above.
Based on the input tuples, predicates at each node and the actual feature value, you should decide on the next step. Some of the possible next steps are clean the input data, add more features, add more training data, try different matcher, etc.
Impact of Imputing Missing Values¶
You should be aware of the following subtleties as it would have an impact when he/she imputes values to feature vector set:
1. When you use the GUI for debugging, you would first choose to see false positives/false negatives and then you would click the debug button to debug that tuple pair. In this case, the feature vector in that row is given as input to find the path traversed in the Decision Tree. If you had imputed the feature vector set to get rid of NaN’s, then the imputed values would be considered to find the path traversed.
2. When you use the command line for debugging, then you would first evaluate the predictions, select false positive or false negative tuple pairs to debug, retrieve the tuples from the left and right tables and finally give them as input to command line debugger commands. If you had imputed the feature vector set to get rid of NaN’s (using a aggregate strategy), then imputed values would not be known to the debugger.
So if the input tables have NaN’s, then the output of the command line debugger would only be partially correct (i.e., the displayed predicates would be correct, but the predicate outcome may differ between current tuple pair and the actual feature vector used during prediction).
Combining Predictions from Multiple Matchers¶
In the matching step, if you use multiple matchers then you will have to combine the predictions from them to get a consolidated prediction. There are many different ways to combine these predictions such as weighted vote, majority vote, stacking, etc. Currently, py_entitymatching supports majority and weighted voting-based combining. These combiners are experimental and not tested.
An example of using majority voting-based combining is shown below.
>>> dt = DTMatcher()
>>> rf = RFMatcher()
>>> nb = NBMatcher()
>>> dt.fit(table=H, exclude_attrs=['_id', 'l_id', 'r_id'], target_attr='label') # H is training set containing feature vectors
>>> dt.predict(table=L, exclude_attrs=['id', 'l_id', 'r_id'], append=True, inplace=True, target_attr='dt_predictions') # L is the test set for which we should get predictions.
>>> rf.fit(table=H, exclude_attrs=['_id', 'l_id', 'r_id'], target_attr='label')
>>> rf.predict(table=L, exclude_attrs=['id', 'l_id', 'r_id'], append=True, inplace=True, target_attr='rf_predictions')
>>> nb.fit(table=H, exclude_attrs=['_id', 'l_id', 'r_id'], target_attr='label')
>>> nb.predict(table=L, exclude_attrs=['id', 'l_id', 'r_id'], append=True, inplace=True, target_attr='nb_predictions')
>>> mv_combiner = MajorityVote()
>>> L['consol_predictions'] = mv_combiner.combine(L[['dt_predictions', 'rf_predictions', 'nb_predictions']])
Conceptually, given a list of predictions (from different matchers) the prediction that occurs most is returned as the consolidated prediction. If there is no clear winning prediction (for example, 0 and 1 occuring equal number of times) then 0 is returned.
An example of using weighted voting-based combining is shown below.
>>> dt = DTMatcher()
>>> rf = RFMatcher()
>>> nb = NBMatcher()
>>> dt.fit(table=H, exclude_attrs=['_id', 'l_id', 'r_id'], target_attr='label') # H is training set containing feature vectors
>>> dt.predict(table=L, exclude_attrs=['id', 'l_id', 'r_id'], append=True, inplace=True, target_attr='dt_predictions') # L is the test set for which we should get predictions.
>>> rf.fit(table=H, exclude_attrs=['_id', 'l_id', 'r_id'], target_attr='label')
>>> rf.predict(table=L, exclude_attrs=['id', 'l_id', 'r_id'], append=True, inplace=True, target_attr='rf_predictions')
>>> nb.fit(table=H, exclude_attrs=['_id', 'l_id', 'r_id'], target_attr='label')
>>> nb.predict(table=L, exclude_attrs=['id', 'l_id', 'r_id'], append=True, inplace=True, target_attr='nb_predictions')
>>> wv_combiner = WeightedVote(weights=[0.3, 0.2, 0.1], threshold=0.4)
>>> L['consol_predictions'] = wv_combiner.combine(L[['dt_predictions',
'rf_predictions', 'nb_predictions']])
Conceptually, given a list of predictions, each prediction is given a weight, we compute a weighted sum of these predictions and compare the result to a threshold. If the result is greater than or equal to the threshold then the consolidated prediction is returned as 1 (i.e., a match) else returned as 0 (no-match).
Using Triggers to Update Matching Results¶
Match Triggers¶
Once you have used a matcher to predict results on a table, you might find that there is some pattern of false positives or false negatives. Often, it is useful to be able to create a set of rules to reevaluate tuple pair predictions to correct these patterns of mistakes.
Creating the Trigger¶
Each trigger can be created by calling its constructor. For example, a user can create a trigger like this:
>>> mt = em.MatchTrigger()
Please refer to MatchTrigger() for more details.
If you have already used a matcher, you should have already created a set of features for matching. More information on this can be found in the section label-create-features-matching.
Once the features are created, py_entitymatching stores this set of features in a feature table. We refer to this feature table as match_f. Then you will be able to instantiate a match trigger and add rules.
Adding and Deleting Rules¶
Once you have created the features, you can create rules like this:
>>> mt = em.MatchTrigger()
>>> mt.add_cond_rule(rule1, match_f)
>>> mt.add_cond_rule(rule2, match_f)
In the above, match_f is a set of features stored as a Dataframe (see section label-create-features-matching).
Each rule is a list of strings. Each string specifies a conjunction of predicates. Each predicate has three parts: (1) an expression, (2) a comparison operator, and (3) a value. The expression is evaluated over a tuple pair, producing a numeric value. Currently, in py_entitymatching an expression is limited to contain a single feature (being applied to a tuple pair). So an example predicate will look like this:
name_name_lev(ltuple, rtuple) > 3
In the above name_name_lev is feature. Concretely, this feature computes Levenshtein distance between the name values in the input tuple pair.
As an example, the rules rule1 and rule2 can look like this:
rule1 = ['name_name_lev(ltuple, rtuple) > 3', 'age_age_exact_match(ltuple, rtuple) !=0']
rule2 = ['address_address_lev(ltuple, rtuple) > 6']
In the above, rule1 contains two predicates and rule2 contains just a single predicate. Each rule is a conjunction of predicates. That is, each rule will return True only if all the predicates return True. The matcher is then a disjunction of rules. That is, even if one of the rules return True, then the result for the tuple pair will be true.
You also need to add a condition status and action when using match triggers. If the result is the same value as the condition status, then the action will be carried out. For example, the action and condition status can be declared like so:
>>> mt.add_cond_status(False)
>>> mt.add_action(0)
The condition status and action in the above example mean that if the rules in the trigger return the value False, then the prediction will be changed to a 0.
Rules can also be deleted once they have been added:
>>> rule_name = mt.add_cond_rule(rule_1, match_f)
>>> mt.delete_rule(rule_name)
The command delete_rule must be given the name of the rule to be deleted. Rule names and information on rules can be found using the following commands:
>>> # get a list of rule names
>>> rule_names = mt.get_rule_names()
>>> # view rule source
>>> mt.view_rule('rule_name')
>>> # get rule fn
>>> mt.get_rule('rule_name')
Executing the Triggers¶
Once the rules, condition status, and action have been specified, the trigger can be used to refine the predictions. An example of using the execute command is shown below:
>>> mt.execute(input_table=H, label_column='prediction_labels', inplace=False)
For more information on the execute method, please refer to
execute() for more details.
Evaluating the Matching Output¶
Once you have predicted matches using ML-based matcher, then you would have to evaluate the matches. py_entitymatching supports eval_matches command for that purpose.
An example of using eval_matches command is shown below:
>>> H = em.extract_feat_vecs(G, feat_table=match_f, attrs_after='gold_labels')
>>> dt = em.DTMatcher()
>>> dt.fit(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels')
>>> pred_table = dt.predict(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], append=True, target_attr='predicted_labels')
>>> eval_summary = em.eval_matches(pred_table, 'gold_labels', 'predicted_labels')
In the above, eval_summary is a dictionary containing accuracy numbers (such as precision, recall, F1, etc) and the list of false positives/negatives.
Please refer to the API reference of eval_matches() for
more details.
Miscellaneous¶
This section covers some miscellaneous things in py_entitymatching.
CSV Format¶
The CSV format is selected because it’s well known and can be read by numerous external programs. Further, it can be easily inspected and edited by the users. You can read more about CSV formats here.
There are two common CSV formats that are used to store CSV files: one with attribute names in the first line, and one without. Both these formats are supported by py_entitymatching.
An example of a CSV file with attribute names is shown below:
ID, name, birth_year, hourly_wage, zipcode
a1, Kevin Smith, 1989, 30, 94107
a2, Michael Franklin, 1988, 27.5, 94122
a3, William Bridge, 1988, 32, 94321
An example of a CSV file with out attribute names is shown below:
a1, Kevin Smith, 1989, 30, 94107
a2, Michael Franklin, 1988, 27.5, 94122
a3, William Bridge, 1988, 32, 94321
Metadata File Format¶
The CSV file can be accompanied with a metadata file containing the metadata information of the table. Typically, it contains information such as key, foreign key, etc. The metadata file is expected to be of the same name as the CSV file but with .metadata extension. For example, if the CSV file table_A.csv contains table A’s data, then table_A.metadata will contain table A’s metadata. So, the metadata is associated based on the names of the files. The metadata file contains key-value pairs one per line and each line starts with ‘#’.
An example of metadata file is shown below:
#key=ID
In the above, the pair key=ID states that ID is the key attribute.
Writing a Dataframe to Disk Along With Its Metadata¶
To write a Dataframe to disk along with its metadata, you can use to_csv_metadata command in py_entitymatching. An example of using to_csv_metadata is shown below:
>>> em.to_csv_metadata(A, './table_A.csv')
The above command will first write Dataframe pointed by A to table_A.csv file in the disk (in CSV format), next it will write the metadata of table A stored in the Catalog to table_A.metadata file in the disk.
Please refer to the API reference of to_csv_metadata() for
more details.
Note
Once the Dataframe is written to disk along with metadata, it can read using read_csv_metadata() command.
Writing/Reading Other Types of py_entitymatching Objects¶
After creating a blocker or feature table, it is desirable to have a way to persist the objects to disk for future use. py_entitymatching provides two commands for that purpose: save_object and load_object.
An example of using save_object is shown below:
>>> block_f = em.get_features_for_blocking(A, B)
>>> rb = em.RuleBasedBlocker()
>>> rb.add_rule([name_name_lev(ltuple, rtuple) < 0.4], block_f)
>>> em.save_object(rb, './rule_based_blocker.pkl')
load_object loads the stored object from disk. An example of using load_object is shown below:
>>> rb = em.load_object('./rule_based_blocker.pkl')
Please refer to the API reference of save_object() and
save_object() for more details.
Overview of Command Organization¶
The commands are organized into two parts. First, the commands that the user will typically use to create an entity matching workflow. Second, a set of experimental commands that are expected to be useful to create an entity matching workflow. Specifically, it includes commands such as dask-based implementations for blockers and combining predictions from a set of matchers. However, the experimental commands are not tested, so use these commands at your own risk.
Commands in py_entitymatching¶
Reading and Writing Data¶
-
py_entitymatching.read_csv_metadata(file_path, **kwargs)¶ Reads a CSV (comma-separated values) file into a pandas DataFrame and update the catalog with the metadata. The CSV files typically contain data for the input tables or a candidate set.
Specifically, this function first reads the CSV file from the given file path into a pandas DataFrame, by using pandas’ in-built ‘read_csv’ method. Then, it updates the catalog with the metadata. There are three ways to update the metadata: (1) using a metadata file, (2) using the key-value parameters supplied in the function, and (3) using both metadata file and key-value parameters.
To update the metadata in the catalog using the metadata file, the function will look for a file in the same directory with same file name but with a specific extension. This extension can be optionally given by the user (defaults to ‘.metadata’). If the metadata file is present, the function will read and update the catalog appropriately. If the metadata file is not present, the function will issue a warning that the metadata file is not present.
The metadata information can also be given as parameters to the function (see description of arguments for more details). If given, the function will update the catalog with the given information.
Further, the metadata can partly reside in the metdata file and partly as supplied parameters. The function will take a union of the two and update the catalog appropriately. If the same metadata is given in both the metadata file and the function, then the metadata in the function takes precedence over the metadata given in the file.
- Parameters
file_path (string) – The CSV file path
kwargs (dictionary) – A Python dictionary containing key-value arguments. There are a few key-value pairs that are specific to read_csv_metadata and all the other key-value pairs are passed to pandas read_csv method
- Returns
A pandas DataFrame read from the input CSV file.
- Raises
AssertionError – If file_path is not of type string.
AssertionError – If a file does not exist in the given file_path.
Examples
Example 1: Read from CSV file and set metadata
>>> A = em.read_csv_metadata('path_to_csv_file', key='id') >>> em.get_key(A) # 'id'
Example 2: Read from CSV file (with metadata file in the same directory
Let the metadata file contain the following contents:
#key = id
>>> A = em.read_csv_metadata('path_to_csv_file') >>> em.get_key(A) # 'id'
See also
-
py_entitymatching.to_csv_metadata(data_frame, file_path, **kwargs)¶ Writes the DataFrame contents to a CSV file and the DataFrame’s metadata (to a separate text file).
This function writes the DataFrame contents to a CSV file in the given file path. It uses ‘to_csv’ method from pandas to write the CSV file. The metadata contents are written to the same directory derived from the file path but with the different extension. This extension can be optionally given by the user (with the default value set to .metadata).
- Parameters
data_frame (DataFrame) – The DataFrame that should be written to disk.
file_path (string) – The file path to which the DataFrame contents should be written. Metadata is written with the same file name with the extension given by the user (defaults to ‘.metadata’).
kwargs (dictionary) – A Python dictionary containing key-value pairs. There is one key-value pair that is specific to to_csv_metadata: metadata_extn. All the other key-value pairs are passed to pandas to_csv function. Here the metadata_extn is the metadata extension (defaults to ‘.metadata’), with which the metadata file must be written.
- Returns
A Boolean value of True is returned if the files were written successfully.
- Raises
AssertionError – If data_frame is not of type pandas DataFrame.
AssertionError – If file_path is not of type string.
AssertionError – If DataFrame cannot be written to the given file_path.
Examples
>>> import pandas as pd >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.set_key(A, 'id') >>> em.to_csv_metadata(A, 'path_to_csv_file')
See also
Loading and Saving Objects¶
-
py_entitymatching.load_table(file_path, metadata_ext='.pklmetadata')¶ Loads a pickled DataFrame from a file along with its metadata.
This function loads a DataFrame from a file stored in pickle format.
Further, this function looks for a metadata file with the same file name but with an extension given by the user (defaults to ‘.pklmetadata’. If the metadata file is present, the function will update the metadata for that DataFrame in the catalog.
- Parameters
file_path (string) – The file path to load the file from.
metadata_ext (string) – The metadata file extension (defaults to ‘.pklmetadata’) that should be used to generate metadata file name.
- Returns
If the loading is successful, the function will return a pandas DataFrame read from the file. The catalog will be updated with the metadata read from the metadata file (if the file was present).
- Raises
AssertionError – If file_path is not of type string.
AssertionError – If metadata_ext is not of type string.
Examples
>>> A = em.load_table('./A.pkl')
>>> A = em.load_table('./A.pkl', metadata_ext='.pklmeta')
See also
Note
This function is different from read_csv_metadata in two aspects. First, this function currently does not support reading in candidate set tables, where there are more metadata such as ltable, rtable than just ‘key’, and conceptually the user is expected to provide ltable and rtable information while calling this function. ( this support will be added shortly). Second, this function loads the table stored in a pickle format.
-
py_entitymatching.save_table(data_frame, file_path, metadata_ext='.pklmetadata')¶ Saves a DataFrame to disk along with its metadata in a pickle format.
This function saves a DataFrame to disk along with its metadata from the catalog.
Specifically, this function saves the DataFrame in the given file path, and saves the metadata in the same directory (as the file path) but with a different extension. This extension can be optionally given by the user (defaults to ‘.pklmetadata’).
- Parameters
data_frame (DataFrame) – The DataFrame that should be saved.
file_path (string) – The file path where the DataFrame must be stored.
metadata_ext (string) – The metadata extension that should be used while storing the metadata information. The default value is ‘.pklmetadata’.
- Returns
A Boolean value of True is returned if the DataFrame is successfully saved.
- Raises
AssertionError – If data_frame is not of type pandas DataFrame.
AssertionError – If file_path is not of type string.
AssertionError – If metadata_ext is not of type string.
AssertionError – If a file cannot written in the given file_path.
Examples
>>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.save_table(A, './A.pkl') # will store two files ./A.pkl and ./A.pklmetadata
>>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.save_table(A, './A.pkl', metadata_ext='.pklmeta') # will store two files ./A.pkl and ./A.pklmeta
See also
Note
This function is a bit different from to_csv_metadata, where the DataFrame is stored in a CSV file format. The CSV file format can be viewed using a text editor. But a DataFrame stored using ‘save_table’ is stored in a special format, which cannot be viewed with a text editor. The reason we have save_table is, for larger DataFrames it is efficient to pickle the DataFrame to disk than writing the DataFrame in CSV format.
-
py_entitymatching.load_object(file_path)¶ Loads a Python object from disk.
This function loads py_entitymatching objects from disk such as blockers, matchers, feature table, etc.
- Parameters
file_path (string) – The file path to load the object from.
- Returns
A Python object read from the file path.
- Raises
AssertionError – If file_path is not of type string.
AssertionError – If a file does not exist at the given file_path.
Examples
>>> rb = em.load_object('./rule_blocker.pkl')
See also
-
py_entitymatching.save_object(object_to_save, file_path)¶ Saves a Python object to disk.
This function is intended to be used to save py_entitymatching objects such as rule-based blocker, feature vectors, etc. A user would like to store py_entitymatching objects to disk, when he/she wants to save the workflow and resume it later. This function provides a way to save the required objects to disk.
This function takes in the object to save the file path. It pickles the object and stores it in the file path specified.
- Parameters
object_to_save (Python object) – The Python object to save. This can be a rule-based blocker, feature vectors, etc.
file_path (string) – The file path where the object must be saved.
- Returns
A Boolean value of True is returned, if the saving was successful.
- Raises
AssertionError – If file_path is not of type string.
AssertionError – If a file cannot be written in the given file_path.
Examples
>>> import pandas as pd >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> B = pd.DataFrame({'id' : [1, 2], 'colA':['c', 'd'], 'colB' : [30, 40]}) >>> rb = em.RuleBasebBlocker() >>> block_f = em.get_features_for_blocking(A, B) >>> rule1 = ['colA_colA_lev_dist(ltuple, rtuple) > 3'] >>> rb.add_rule(rule1) >>> em.save_object(rb, './rule_blocker.pkl')
See also
Handling Metadata¶
-
py_entitymatching.get_catalog()¶ Gets the catalog information for the current session.
- Returns
A Python dictionary containing the catalog information.
Specifically, the dictionary contains the Python identifier of a DataFrame (obtained by id(DataFrame object)) as the key and their properties as value.
Examples
>>> import py_entitymatching as em >>> catalog = em.get_catalog()
-
py_entitymatching.get_catalog_len()¶ Get the length (i.e the number of entries) in the catalog.
- Returns
The number of entries in the catalog as an integer.
Examples
>>> import py_entitymatching as em >>> len = em.get_catalog_len()
-
py_entitymatching.del_catalog()¶ Deletes the catalog for the current session.
- Returns
A Boolean value of True is returned if the deletion was successful.
Examples
>>> import py_entitymatching as em >>> em.del_catalog()
-
py_entitymatching.is_catalog_empty()¶ Checks if the catalog is empty.
- Returns
A Boolean value of True is returned if the catalog is empty, else returns False.
Examples
>>> import py_entitymatching as em >>> import pandas as pd >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.set_key(A, 'id') >>> em.is_catalog_empty() # False
-
py_entitymatching.is_dfinfo_present(data_frame)¶ Checks whether the DataFrame information is present in the catalog.
- Parameters
data_frame (DataFrame) – The DataFrame that should be checked for its presence in the catalog.
- Returns
A Boolean value of True is returned if the DataFrame is present in the catalog, else False is returned.
- Raises
AssertionError – If data_frame is not of type pandas DataFrame.
Examples
>>> import py_entitymatching as em >>> import pandas as pd >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.set_key(A, 'id') >>> em.is_dfinfo_present(A) # True
-
py_entitymatching.is_property_present_for_df(data_frame, property_name)¶ Checks if the given property is present for the given DataFrame in the catalog.
- Parameters
data_frame (DataFrame) – The DataFrame for which the property must be checked for.
property_name (string) – The name of the property that should be
for its presence for the DataFrame, in the catalog. (checked) –
- Returns
A Boolean value of True is returned if the property is present for the given DataFrame.
- Raises
AssertionError – If data_frame is not of type pandas DataFrame.
AssertionError – If property_name is not of type string.
KeyError – If data_frame is not present in the catalog.
Examples
>>> import py_entitymatching as em >>> import pandas as pd >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.set_key(A, 'id') >>> em.is_property_present_for_df(A, 'id') # True >>> em.is_property_present_for_df(A, 'fk_ltable') # False
-
py_entitymatching.show_properties(data_frame)¶ Prints the properties for a DataFrame that is present in the catalog.
- Parameters
data_frame (DataFrame) – The input pandas DataFrame for which the properties must be displayed.
Examples
>>> A = pd.DataFrame({'key_attr' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.set_key(A, 'key_attr') >>> em.show_properties(A) # id: 4572922488 # This will change dynamically # key: key_attr
-
py_entitymatching.show_properties_for_id(object_id)¶ Shows the properties for an object id present in the catalog.
Specifically, given an object id got from typically executing id( <object>), where the object could be a DataFrame, this function will display the properties present for that object id in the catalog.
- Parameters
object_id (int) – The Python identifier of an object (typically a pandas DataFrame).
Examples
>>> A = pd.DataFrame({'key_attr' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.set_key(A, 'key_attr') >>> em.show_properties_for_id(id(A)) # id: 4572922488 # This will change dynamically # key: key_attr
-
py_entitymatching.get_property(data_frame, property_name)¶ Gets the value of a property (with the given property name) for a pandas DataFrame from the catalog.
- Parameters
data_frame (DataFrame) – The DataFrame for which the property should be retrieved.
property_name (string) – The name of the property that should be retrieved.
- Returns
A Python object (typically a string or a pandas DataFrame depending on the property name) is returned.
- Raises
AssertionError – If data_frame is not of type pandas DataFrame.
AssertionError – If property_name is not of type string.
KeyError – If data_frame information is not present in the catalog.
KeyError – If requested property for the data_frame is not present in the catalog.
Examples
>>> import py_entitymatching as em >>> import pandas as pd >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.set_key(A, 'id') >>> em.get_property(A, 'key') # id
-
py_entitymatching.set_property(data_frame, property_name, property_value)¶ Sets the value of a property (with the given property name) for a pandas DataFrame in the catalog.
- Parameters
data_frame (DataFrame) – The DataFrame for which the property must be set.
property_name (string) – The name of the property to be set.
property_value (object) – The value of the property to be set. This is typically a string (such as key) or pandas DataFrame (such as ltable, rtable).
- Returns
A Boolean value of True is returned if the update was successful.
- Raises
AssertionError – If data_frame is not of type pandas DataFrame.
AssertionError – If property_name is not of type string.
Examples
>>> import py_entitymatching as em >>> import pandas as pd >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.set_property(A, 'key', 'id') >>> em.get_property(A, 'key') # id >>> em.get_key(A) # id
Note
If the input DataFrame is not present in the catalog, this function will create an entry in the catalog and set the given property.
-
py_entitymatching.del_property(data_frame, property_name)¶ Deletes a property for a pandas DataFrame from the catalog.
- Parameters
data_frame (DataFrame) – The input DataFrame for which a property must be deleted from the catalog.
property_name (string) – The name of the property that should be deleted.
- Returns
A Boolean value of True is returned if the deletion was successful.
- Raises
AssertionError – If data_frame is not of type pandas DataFrame.
AssertionError – If property_name is not of type string.
KeyError – If data_frame information is not present in the catalog.
KeyError – If requested property for the DataFrame is not present in the catalog.
Examples
>>> import py_entitymatching as em >>> import pandas as pd >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.set_property(A, 'key', 'id') >>> em.get_property(A, 'key') # id >>> em.del_property(A, 'key') >>> em.is_property_present_for_df(A, 'key') # False
-
py_entitymatching.copy_properties(source_data_frame, target_data_frame, replace=True)¶ Copies properties from a source DataFrame to target DataFrame in the catalog.
- Parameters
source_data_frame (DataFrame) – The DataFrame from which the properties to be copied from, in the catalog.
target_data_frame (DataFrame) – The DataFrame to which the properties to be copied to, in the catalog.
replace (boolean) – A flag to indicate whether the source DataFrame’s properties can replace the target DataFrame’s properties in the catalog. The default value for the flag is True. Specifically, if the target DataFrame’s information is already present in the catalog then the function will check if the replace flag is True. If the flag is set to True, then the function will first delete the existing properties and then set it with the source DataFrame properties. If the flag is False, the function will just return without modifying the existing properties.
- Returns
A Boolean value of True is returned if the copying was successful.
- Raises
AssertionError – If source_data_frame is not of type pandas DataFrame.
AssertionError – If target_data_frame is not of type pandas DataFrame.
KeyError – If source DataFrame is not present in the catalog.
Examples
>>> import py_entitymatching as em >>> import pandas as pd >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.set_key(A, 'id') >>> B = pd.DataFrame({'id' : [1, 2], 'colA':['c', 'd'], 'colB' : [30, 40]}) >>> em.copy_properties(A, B) >>> em.get_key(B) # 'id'
-
py_entitymatching.get_key(data_frame)¶ Gets the value of ‘key’ property for a DataFrame from the catalog.
- Parameters
data_frame (DataFrame) – The DataFrame for which the key must be retrieved from the catalog.
- Returns
A string value containing the key column name is returned (if present).
Examples
>>> import py_entitymatching as em >>> import pandas as pd >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.set_key(A, 'id') >>> em.get_key(A) # 'id'
See also
-
py_entitymatching.set_key(data_frame, key_attribute)¶ Sets the value of ‘key’ property for a DataFrame in the catalog with the given attribute (i.e column name).
Specifically, this function set the the key attribute for the DataFrame if the given attribute satisfies the following two properties:
The key attribute should have unique values.
The key attribute should not have missing values. A missing value is represented as np.NaN.
- Parameters
data_frame (DataFrame) – The DataFrame for which the key must be set in the catalog.
key_attribute (string) – The key attribute (column name) in the DataFrame.
- Returns
A Boolean value of True is returned, if the given attribute satisfies the conditions for a key and the update was successful.
- Raises
AssertionError – If data_frame is not of type pandas DataFrame.
AssertionError – If key_attribute is not of type string.
KeyError – If given key_attribute is not in the DataFrame columns.
Examples
>>> import py_entitymatching as em >>> import pandas as pd >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> em.set_key(A, 'id') >>> em.get_key(A) # 'id'
See also
-
py_entitymatching.get_fk_ltable(data_frame)¶ Gets the foreign key to left table for a DataFrame from the catalog.
Specifically this function is a sugar function that will get the foreign key to left table using underlying
get_property()function. This function is typically called on a DataFrame which contains metadata such as fk_ltable, fk_rtable, ltable, rtable.- Parameters
data_frame (DataFrame) – The input DataFrame for which the foreign key ltable property must be retrieved.
- Returns
A Python object, typically a string is returned.
Examples
>>> import py_entitymatching as em >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> B = pd.DataFrame({'id' : [1, 2], 'colA':['c', 'd'], 'colB' : [30, 40]}) >>> em.set_key(A, 'id') >>> em.set_key(B, 'id') >>> C = pd.DataFrame({'id':[1, 2], 'ltable_id':[1, 2], 'rtable_id':[2, 1]}) >>> em.set_key(C, 'id') >>> em.set_fk_ltable(C, 'ltable_id') >>> em.get_fk_ltable(C) # 'ltable_id'
See also
-
py_entitymatching.set_fk_ltable(data_frame, fk_ltable)¶ Sets the foreign key to ltable for a DataFrame in the catalog.
Specifically this function is a sugar function that will set the foreign key to the left table using
py_entitymatching.set_property()function. This function is typically called on a DataFrame which contains metadata such as fk_ltable, fk_rtable, ltable, rtable.- Parameters
data_frame (DataFrame) – The input DataFrame for which the foreign key ltable property must be set.
fk_ltable (string) – The attribute that must ne set as the foreign key to the ltable in the catalog.
- Returns
A Boolean value of True is returned if the foreign key to ltable was set successfully.
- Raises
AssertionError – If data_frame is not of type pandas DataFrame.
AssertionError – If fk_ltable is not of type string.
AssertionError – If fk_ltable is not in the input DataFrame.
Examples
>>> import py_entitymatching as em >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> B = pd.DataFrame({'id' : [1, 2], 'colA':['c', 'd'], 'colB' : [30, 40]}) >>> em.set_key(A, 'id') >>> em.set_key(B, 'id') >>> C = pd.DataFrame({'id':[1, 2], 'ltable_id':[1, 2], 'rtable_id':[2, 1]}) >>> em.set_key(C, 'id') >>> em.set_fk_ltable(C, 'ltable_id') >>> em.get_fk_ltable(C) # 'ltable_id'
See also
-
py_entitymatching.get_fk_rtable(data_frame)¶ Gets the foreign key to right table for a DataFrame from the catalog.
Specifically this function is a sugar function that will get the foreign key to right table using
py_entitymatching.get_property()function. This function is typically called on a DataFrame which contains metadata such as fk_ltable, fk_rtable, ltable, rtable.- Parameters
data_frame (DataFrame) – The input DataFrame for which the foreign key rtable property must be retrieved.
- Returns
A Python object, (typically a string) is returned.
Examples
>>> import py_entitymatching as em >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> B = pd.DataFrame({'id' : [1, 2], 'colA':['c', 'd'], 'colB' : [30, 40]}) >>> em.set_key(A, 'id') >>> em.set_key(B, 'id') >>> C = pd.DataFrame({'id':[1, 2], 'ltable_id':[1, 2], 'rtable_id':[2, 1]}) >>> em.set_key(C, 'id') >>> em.set_fk_rtable(C, 'rtable_id') >>> em.get_fk_rtable(C) # 'rtable_id'
See also
-
py_entitymatching.set_fk_rtable(data_frame, foreign_key_rtable)¶ Sets the foreign key to rtable for a DataFrame in the catalog.
Specifically this function is a sugar function that will set the foreign key to right table using set_property function. This function is typically called on a DataFrame which contains metadata such as fk_ltable, fk_rtable, ltable, rtable.
- Parameters
data_frame (DataFrame) – The input DataFrame for which the foreign key rtable property must be set.
foreign_key_rtable (string) – The attribute that must be set as foreign key to rtable in the catalog.
- Returns
- A Boolean value of True is returned if the foreign key to rtable was
set successfully.
- Raises
AssertionError – If data_frame is not of type pandas DataFrame.
AssertionError – If foreign_key_rtable is not of type string.
AssertionError – If fk_rtable is not in the input DataFrame.
Examples
>>> import py_entitymatching as em >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> B = pd.DataFrame({'id' : [1, 2], 'colA':['c', 'd'], 'colB' : [30, 40]}) >>> em.set_key(A, 'id') >>> em.set_key(B, 'id') >>> C = pd.DataFrame({'id':[1, 2], 'ltable_id':[1, 2], 'rtable_id':[2, 1]}) >>> em.set_key(C, 'id') >>> em.set_fk_rtable(C, 'rtable_id') >>> em.get_fk_rtable(C) # 'rtable_id'
See also
-
py_entitymatching.get_ltable(candset)¶ Gets the ltable for a DataFrame from the catalog.
- Parameters
candset (DataFrame) – The input table for which the ltable must be returned.
- Returns
A pandas DataFrame that is pointed by ‘ltable’ property of the input table.
Examples
>>> import py_entitymatching as em >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> B = pd.DataFrame({'id' : [1, 2], 'colA':['c', 'd'], 'colB' : [30, 40]}) >>> em.set_key(A, 'id') >>> em.set_key(B, 'id') >>> C = pd.DataFrame({'id':[1, 2], 'ltable_id':[1, 2], 'rtable_id':[2, 1]}) >>> em.set_key(C, 'id') >>> em.set_ltable(C, A) >>> id(em.get_ltable(A) == id(A) # True
See also
-
py_entitymatching.set_ltable(candset, table)¶ Sets the ltable for a DataFrame in the catalog.
- Parameters
candset (DataFrame) – The input table for which the ltable must be set.
table (DataFrame) – The table (typically a pandas DataFrame) that must be set as ltable for the input DataFrame.
- Returns
A Boolean value of True is returned, if the update was successful.
Examples
>>> import py_entitymatching as em >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> B = pd.DataFrame({'id' : [1, 2], 'colA':['c', 'd'], 'colB' : [30, 40]}) >>> em.set_key(A, 'id') >>> em.set_key(B, 'id') >>> C = pd.DataFrame({'id':[1, 2], 'ltable_id':[1, 2], 'rtable_id':[2, 1]}) >>> em.set_key(C, 'id') >>> em.set_ltable(C, A) >>> id(em.get_ltable(A) == id(A) # True
See also
-
py_entitymatching.get_rtable(candset)¶ Gets the rtable for a DataFrame from the catalog.
- Parameters
candset (DataFrame) – Input table for which the rtable must be returned.
- Returns
A pandas DataFrame that is pointed by ‘rtable’ property of the input table.
Examples
>>> import py_entitymatching as em >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> B = pd.DataFrame({'id' : [1, 2], 'colA':['c', 'd'], 'colB' : [30, 40]}) >>> em.set_key(A, 'id') >>> em.set_key(B, 'id') >>> C = pd.DataFrame({'id':[1, 2], 'ltable_id':[1, 2], 'rtable_id':[2, 1]}) >>> em.set_key(C, 'id') >>> em.set_rtable(C, B) >>> id(em.get_rtable(B) == id(B) # True
See also
-
py_entitymatching.set_rtable(candset, table)¶ Sets the rtable for a DataFrame in the catalog.
- Parameters
candset (DataFrame) – The input table for which the rtable must be set.
table (DataFrame) – The table that must be set as rtable for the input DataFrame.
- Returns
A Boolean value of True is returned, if the update was successful.
Examples
>>> import py_entitymatching as em >>> A = pd.DataFrame({'id' : [1, 2], 'colA':['a', 'b'], 'colB' : [10, 20]}) >>> B = pd.DataFrame({'id' : [1, 2], 'colA':['c', 'd'], 'colB' : [30, 40]}) >>> em.set_key(A, 'id') >>> em.set_key(B, 'id') >>> C = pd.DataFrame({'id':[1, 2], 'ltable_id':[1, 2], 'rtable_id':[2, 1]}) >>> em.set_key(C, 'id') >>> em.set_rtable(C, B) >>> id(em.get_rtable(B) == id(B) # True
See also
Downsampling¶
-
py_entitymatching.down_sample(table_a, table_b, size, y_param, show_progress=True, verbose=False, seed=None, rem_stop_words=True, rem_puncs=True, n_jobs=1)¶ This function down samples two tables A and B into smaller tables A’ and B’ respectively.
Specifically, first it randomly selects size tuples from the table B to be table B’. Next, it builds an inverted index I (token, tuple_id) on table A. For each tuple x ∈ B’, the algorithm finds a set P of k/2 tuples from I that match x, and a set Q of k/2 tuples randomly selected from A - P. The idea is for A’ and B’ to share some matches yet be as representative of A and B as possible.
- Parameters
table_a,table_b (DataFrame) – The input tables A and B.
size (int) – The size that table B should be down sampled to.
y_param (int) – The parameter to control the down sample size of table A. Specifically, the down sampled size of table A should be close to size * y_param.
show_progress (boolean) – A flag to indicate whether a progress bar should be displayed (defaults to True).
verbose (boolean) – A flag to indicate whether the debug information should be displayed (defaults to False).
seed (int) – The seed for the pseudo random number generator to select the tuples from A and B (defaults to None).
rem_stop_words (boolean) – A flag to indicate whether a default set of stop words must be removed.
rem_puncs (boolean) – A flag to indicate whether the punctuations must be removed from the strings.
n_jobs (int) – The number of parallel jobs to be used for computation (defaults to 1). If -1 all CPUs are used. If 0 or 1, no parallel computation is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used (where n_cpus is the total number of CPUs in the machine). Thus, for n_jobs = -2, all CPUs but one are used. If (n_cpus + 1 + n_jobs) is less than 1, then no parallel computation is used (i.e., equivalent to the default).
- Returns
Down sampled tables A and B as pandas DataFrames.
- Raises
AssertionError – If any of the input tables (table_a, table_b) are empty or not a DataFrame.
AssertionError – If size or y_param is empty or 0 or not a valid integer value.
AssertionError – If seed is not a valid integer value.
AssertionError – If verbose is not of type bool.
AssertionError – If show_progress is not of type bool.
AssertionError – If n_jobs is not of type int.
Examples
>>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> sample_A, sample_B = em.down_sample(A, B, 500, 1, n_jobs=-1)
# Example with seed = 0. This means the same sample data set will be returned # each time this function is run. >>> A = em.read_csv_metadata(‘path_to_csv_dir/table_A.csv’, key=’ID’) >>> B = em.read_csv_metadata(‘path_to_csv_dir/table_B.csv’, key=’ID’) >>> sample_A, sample_B = em.down_sample(A, B, 500, 1, seed=0, n_jobs=-1)
Data Exploration¶
-
class
py_entitymatching.data_explore_openrefine¶ Wrapper function for using OpenRefine. Gives user a GUI to examine and edit the dataframe passed in using OpenRefine.
- Parameters
df (Dataframe) – The pandas dataframe to be explored with pandastable.
server (String) – The address of the OpenRefine server (defaults to http://127.0.0.1:3333).
name (String) – The name given to the file and project in OpenRefine.
- Raises
AssertionError – If df is not of type pandas DataFrame.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table.csv', key='ID') >>> em.data_explore_openrefine(A, name='Table')
-
class
py_entitymatching.data_explore_pandastable¶ Wrapper function for pandastable. Gives user a GUI to examine and edit the dataframe passed in using pandastable.
- Parameters
df (Dataframe) – The pandas dataframe to be explored with pandastable.
- Raises
AssertionError – If df is not of type pandas DataFrame.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table.csv', key='ID') >>> em.data_explore_pandastable(A)
Blocking¶
-
class
py_entitymatching.AttrEquivalenceBlocker¶ Blocks based on the equivalence of attribute values.
-
block_candset(candset, l_block_attr, r_block_attr, allow_missing=False, verbose=False, show_progress=True, n_jobs=1)¶ Blocks an input candidate set of tuple pairs based on attribute equivalence.
Finds tuple pairs from an input candidate set of tuple pairs such that the value of attribute l_block_attr of the left tuple in a tuple pair exactly matches the value of attribute r_block_attr of the right tuple in the tuple pair.
- Parameters
candset (DataFrame) – The input candidate set of tuple pairs.
l_block_attr (string) – The blocking attribute in left table.
r_block_attr (string) – The blocking attribute in right table.
allow_missing (boolean) – A flag to indicate whether tuple pairs with missing value in at least one of the blocking attributes should be included in the output candidate set (defaults to False). If this flag is set to True, a tuple pair with missing value in either blocking attribute will be retained in the output candidate set.
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_jobs (int) – The number of parallel jobs to be used for computation (defaults to 1). If -1 all CPUs are used. If 0 or 1, no parallel computation is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used (where n_cpus is the total number of CPUs in the machine). Thus, for n_jobs = -2, all CPUs but one are used. If (n_cpus + 1 + n_jobs) is less than 1, then no parallel computation is used (i.e., equivalent to the default).
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If candset is not of type pandas DataFrame.
AssertionError – If l_block_attr is not of type string.
AssertionError – If r_block_attr is not of type string.
AssertionError – If verbose is not of type boolean.
AssertionError – If n_jobs is not of type int.
AssertionError – If l_block_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> ab = em.AttrEquivalenceBlocker() >>> C = ab.block_tables(A, B, 'zipcode', 'zipcode', l_output_attrs=['name'], r_output_attrs=['name'])
>>> D1 = ab.block_candset(C, 'age', 'age', allow_missing=True) # Include all possible tuple pairs with missing values >>> D2 = ab.block_candset(C, 'age', 'age', allow_missing=True) # Execute blocking using multiple cores >>> D3 = ab.block_candset(C, 'age', 'age', n_jobs=-1)
-
block_tables(ltable, rtable, l_block_attr, r_block_attr, l_output_attrs=None, r_output_attrs=None, l_output_prefix='ltable_', r_output_prefix='rtable_', allow_missing=False, verbose=False, n_jobs=1)¶ Blocks two tables based on attribute equivalence.
Conceptually, this will check l_block_attr=r_block_attr for each tuple pair from the Cartesian product of tables ltable and rtable. It outputs a Pandas dataframe object with tuple pairs that satisfy the equality condition. The dataframe will include attributes ‘_id’, key attribute from ltable, key attributes from rtable, followed by lists l_output_attrs and r_output_attrs if they are specified. Each of these output and key attributes will be prefixed with given l_output_prefix and r_output_prefix. If allow_missing is set to True then all tuple pairs with missing value in at least one of the tuples will be included in the output dataframe. Further, this will update the following metadata in the catalog for the output table: (1) key, (2) ltable, (3) rtable, (4) fk_ltable, and (5) fk_rtable.
- Parameters
ltable (DataFrame) – The left input table.
rtable (DataFrame) – The right input table.
l_block_attr (string) – The blocking attribute in left table.
r_block_attr (string) – The blocking attribute in right table.
l_output_attrs (list) – A list of attribute names from the left table to be included in the output candidate set (defaults to None).
r_output_attrs (list) – A list of attribute names from the right table to be included in the output candidate set (defaults to None).
l_output_prefix (string) – The prefix to be used for the attribute names coming from the left table in the output candidate set (defaults to ‘ltable_’).
r_output_prefix (string) – The prefix to be used for the attribute names coming from the right table in the output candidate set (defaults to ‘rtable_’).
allow_missing (boolean) – A flag to indicate whether tuple pairs with missing value in at least one of the blocking attributes should be included in the output candidate set (defaults to False). If this flag is set to True, a tuple in ltable with missing value in the blocking attribute will be matched with every tuple in rtable and vice versa.
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
n_jobs (int) – The number of parallel jobs to be used for computation (defaults to 1). If -1 all CPUs are used. If 0 or 1, no parallel computation is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used (where n_cpus is the total number of CPUs in the machine). Thus, for n_jobs = -2, all CPUs but one are used. If (n_cpus + 1 + n_jobs) is less than 1, then no parallel computation is used (i.e., equivalent to the default).
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
AssertionError – If l_block_attr is not of type string.
AssertionError – If r_block_attr is not of type string.
AssertionError – If l_output_attrs is not of type of list.
AssertionError – If r_output_attrs is not of type of list.
AssertionError – If the values in l_output_attrs is not of type string.
AssertionError – If the values in r_output_attrs is not of type string.
AssertionError – If l_output_prefix is not of type string.
AssertionError – If r_output_prefix is not of type string.
AssertionError – If verbose is not of type boolean.
AssertionError – If allow_missing is not of type boolean.
AssertionError – If n_jobs is not of type int.
AssertionError – If l_block_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
AssertionError – If l_out_attrs are not in the ltable.
AssertionError – If r_out_attrs are not in the rtable.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> ab = em.AttrEquivalenceBlocker() >>> C1 = ab.block_tables(A, B, 'zipcode', 'zipcode', l_output_attrs=['name'], r_output_attrs=['name']) # Include all possible tuple pairs with missing values >>> C2 = ab.block_tables(A, B, 'zipcode', 'zipcode', l_output_attrs=['name'], r_output_attrs=['name'], allow_missing=True)
-
block_tuples(ltuple, rtuple, l_block_attr, r_block_attr, allow_missing=False)¶ Blocks a tuple pair based on attribute equivalence.
- Parameters
ltuple (Series) – The input left tuple.
rtuple (Series) – The input right tuple.
l_block_attr (string) – The blocking attribute in left tuple.
r_block_attr (string) – The blocking attribute in right tuple.
allow_missing (boolean) – A flag to indicate whether a tuple pair with missing value in at least one of the blocking attributes should be blocked (defaults to False). If this flag is set to True, the pair will be kept if either ltuple has missing value in l_block_attr or rtuple has missing value in r_block_attr or both.
- Returns
A status indicating if the tuple pair is blocked, i.e., the values of l_block_attr in ltuple and r_block_attr in rtuple are different (boolean).
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> ab = em.AttrEquivalenceBlocker() >>> status = ab.block_tuples(A.ix[0], B.ix[0], 'zipcode', 'zipcode')
-
-
class
py_entitymatching.OverlapBlocker¶ Blocks based on the overlap of token sets of attribute values.
-
block_candset(candset, l_overlap_attr, r_overlap_attr, rem_stop_words=False, q_val=None, word_level=True, overlap_size=1, allow_missing=False, verbose=False, show_progress=True, n_jobs=1)¶ - Blocks an input candidate set of tuple pairs based on the overlap
of token sets of attribute values.
Finds tuple pairs from an input candidate set of tuple pairs such that the overlap between (a) the set of tokens obtained by tokenizing the value of attribute l_overlap_attr of the left tuple in a tuple pair, and (b) the set of tokens obtained by tokenizing the value of attribute r_overlap_attr of the right tuple in the tuple pair, is above a certain threshold.
- Parameters
candset (DataFrame) – The input candidate set of tuple pairs.
l_overlap_attr (string) – The overlap attribute in left table.
r_overlap_attr (string) – The overlap attribute in right table.
rem_stop_words (boolean) – A flag to indicate whether stop words (e.g., a, an, the) should be removed from the token sets of the overlap attribute values (defaults to False).
q_val (int) – The value of q to use if the overlap attributes values are to be tokenized as qgrams (defaults to None).
word_level (boolean) – A flag to indicate whether the overlap attributes should be tokenized as words (i.e, using whitespace as delimiter) (defaults to True).
overlap_size (int) – The minimum number of tokens that must overlap (defaults to 1).
allow_missing (boolean) – A flag to indicate whether tuple pairs with missing value in at least one of the blocking attributes should be included in the output candidate set (defaults to False). If this flag is set to True, a tuple pair with missing value in either blocking attribute will be retained in the output candidate set.
verbose (boolean) –
A flag to indicate whether the debug information
should be logged (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_jobs (int) – The number of parallel jobs to be used for computation (defaults to 1). If -1 all CPUs are used. If 0 or 1, no parallel computation is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used (where n_cpus are the total number of CPUs in the machine).Thus, for n_jobs = -2, all CPUs but one are used. If (n_cpus + 1 + n_jobs) is less than 1, then no parallel computation is used (i.e., equivalent to the default).
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If candset is not of type pandas DataFrame.
AssertionError – If l_overlap_attr is not of type string.
AssertionError – If r_overlap_attr is not of type string.
AssertionError – If q_val is not of type int.
AssertionError – If word_level is not of type boolean.
AssertionError – If overlap_size is not of type int.
AssertionError – If verbose is not of type boolean.
AssertionError – If allow_missing is not of type boolean.
AssertionError – If show_progress is not of type boolean.
AssertionError – If n_jobs is not of type int.
AssertionError – If l_overlap_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
SyntaxError – If q_val is set to a valid value and word_level is set to True.
SyntaxError – If q_val is set to None and word_level is set to False.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> ob = em.OverlapBlocker() >>> C = ob.block_tables(A, B, 'address', 'address', l_output_attrs=['name'], r_output_attrs=['name'])
>>> D1 = ob.block_candset(C, 'name', 'name', allow_missing=True) # Include all possible tuple pairs with missing values >>> D2 = ob.block_candset(C, 'name', 'name', allow_missing=True) # Execute blocking using multiple cores >>> D3 = ob.block_candset(C, 'name', 'name', n_jobs=-1) # Use q-gram tokenizer >>> D2 = ob.block_candset(C, 'name', 'name', word_level=False, q_val=2)
-
block_tables(ltable, rtable, l_overlap_attr, r_overlap_attr, rem_stop_words=False, q_val=None, word_level=True, overlap_size=1, l_output_attrs=None, r_output_attrs=None, l_output_prefix='ltable_', r_output_prefix='rtable_', allow_missing=False, verbose=False, show_progress=True, n_jobs=1)¶ - Blocks two tables based on the overlap of token sets of attribute
values.
Finds tuple pairs from left and right tables such that the overlap between (a) the set of tokens obtained by tokenizing the value of attribute l_overlap_attr of a tuple from the left table, and (b) the set of tokens obtained by tokenizing the value of attribute r_overlap_attr of a tuple from the right table, is above a certain threshold.
- Parameters
ltable (DataFrame) – The left input table.
rtable (DataFrame) – The right input table.
l_overlap_attr (string) – The overlap attribute in left table.
r_overlap_attr (string) – The overlap attribute in right table.
rem_stop_words (boolean) – A flag to indicate whether stop words (e.g., a, an, the) should be removed from the token sets of the overlap attribute values (defaults to False).
q_val (int) – The value of q to use if the overlap attributes values are to be tokenized as qgrams (defaults to None).
word_level (boolean) – A flag to indicate whether the overlap attributes should be tokenized as words (i.e, using whitespace as delimiter) (defaults to True).
overlap_size (int) – The minimum number of tokens that must overlap (defaults to 1).
l_output_attrs (list) – A list of attribute names from the left table to be included in the output candidate set (defaults to None).
r_output_attrs (list) – A list of attribute names from the right table to be included in the output candidate set (defaults to None).
l_output_prefix (string) – The prefix to be used for the attribute names coming from the left table in the output candidate set (defaults to ‘ltable_’).
r_output_prefix (string) – The prefix to be used for the attribute names coming from the right table in the output candidate set (defaults to ‘rtable_’).
allow_missing (boolean) – A flag to indicate whether tuple pairs with missing value in at least one of the blocking attributes should be included in the output candidate set (defaults to False). If this flag is set to True, a tuple in ltable with missing value in the blocking attribute will be matched with every tuple in rtable and vice versa.
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_jobs (int) – The number of parallel jobs to be used for computation (defaults to 1). If -1 all CPUs are used. If 0 or 1, no parallel computation is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used (where n_cpus is the total number of CPUs in the machine). Thus, for n_jobs = -2, all CPUs but one are used. If (n_cpus + 1 + n_jobs) is less than 1, then no parallel computation is used (i.e., equivalent to the default).
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
AssertionError – If l_overlap_attr is not of type string.
AssertionError – If r_overlap_attr is not of type string.
AssertionError – If l_output_attrs is not of type of list.
AssertionError – If r_output_attrs is not of type of list.
AssertionError – If the values in l_output_attrs is not of type string.
AssertionError – If the values in r_output_attrs is not of type string.
AssertionError – If l_output_prefix is not of type string.
AssertionError – If r_output_prefix is not of type string.
AssertionError – If q_val is not of type int.
AssertionError – If word_level is not of type boolean.
AssertionError – If overlap_size is not of type int.
AssertionError – If verbose is not of type boolean.
AssertionError – If allow_missing is not of type boolean.
AssertionError – If show_progress is not of type boolean.
AssertionError – If n_jobs is not of type int.
AssertionError – If l_overlap_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
AssertionError – If l_output_attrs are not in the ltable.
AssertionError – If r_output_attrs are not in the rtable.
SyntaxError – If q_val is set to a valid value and word_level is set to True.
SyntaxError – If q_val is set to None and word_level is set to False.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> ob = em.OverlapBlocker() # Use word-level tokenizer >>> C1 = ob.block_tables(A, B, 'address', 'address', l_output_attrs=['name'], r_output_attrs=['name'], word_level=True, overlap_size=1) # Use q-gram tokenizer >>> C2 = ob.block_tables(A, B, 'address', 'address', l_output_attrs=['name'], r_output_attrs=['name'], word_level=False, q_val=2) # Include all possible missing values >>> C3 = ob.block_tables(A, B, 'address', 'address', l_output_attrs=['name'], r_output_attrs=['name'], allow_missing=True) # Use all the cores in the machine >>> C3 = ob.block_tables(A, B, 'address', 'address', l_output_attrs=['name'], r_output_attrs=['name'], n_jobs=-1)
-
block_tuples(ltuple, rtuple, l_overlap_attr, r_overlap_attr, rem_stop_words=False, q_val=None, word_level=True, overlap_size=1, allow_missing=False)¶ - Blocks a tuple pair based on the overlap of token sets of attribute
values.
- Parameters
ltuple (Series) – The input left tuple.
rtuple (Series) – The input right tuple.
l_overlap_attr (string) – The overlap attribute in left tuple.
r_overlap_attr (string) – The overlap attribute in right tuple.
rem_stop_words (boolean) – A flag to indicate whether stop words (e.g., a, an, the) should be removed from the token sets of the overlap attribute values (defaults to False).
q_val (int) – A value of q to use if the overlap attributes values are to be tokenized as qgrams (defaults to None).
word_level (boolean) – A flag to indicate whether the overlap attributes should be tokenized as words (i.e, using whitespace as delimiter) (defaults to True).
overlap_size (int) – The minimum number of tokens that must overlap (defaults to 1).
allow_missing (boolean) – A flag to indicate whether a tuple pair with missing value in at least one of the blocking attributes should be blocked (defaults to False). If this flag is set to True, the pair will be kept if either ltuple has missing value in l_block_attr or rtuple has missing value in r_block_attr or both.
- Returns
A status indicating if the tuple pair is blocked (boolean).
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> ob = em.OverlapBlocker() >>> status = ob.block_tuples(A.ix[0], B.ix[0], 'address', 'address')
-
-
class
py_entitymatching.RuleBasedBlocker(*args, **kwargs)¶ Blocks based on a sequence of blocking rules supplied by the user.
-
add_rule(conjunct_list, feature_table=None, rule_name=None)¶ Adds a rule to the rule-based blocker.
- Parameters
conjunct_list (list) – A list of conjuncts specifying the rule.
feature_table (DataFrame) – A DataFrame containing all the features that are being referenced by the rule (defaults to None). If the feature_table is not supplied here, then it must have been specified during the creation of the rule-based blocker or using set_feature_table function. Otherwise an AssertionError will be raised and the rule will not be added to the rule-based blocker.
rule_name (string) – A string specifying the name of the rule to be added (defaults to None). If the rule_name is not specified then a name will be automatically chosen. If there is already a rule with the specified rule_name, then an AssertionError will be raised and the rule will not be added to the rule-based blocker.
- Returns
The name of the rule added (string).
- Raises
AssertionError – If rule_name already exists.
AssertionError – If feature_table is not a valid value parameter.
Examples
>>> import py_entitymatching as em >>> rb = em.RuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, rule_name='rule1')
-
block_candset(candset, verbose=False, show_progress=True, n_jobs=1)¶ Blocks an input candidate set of tuple pairs based on a sequence of blocking rules supplied by the user.
Finds tuple pairs from an input candidate set of tuple pairs that survive the sequence of blocking rules. A tuple pair survives the sequence of blocking rules if none of the rules in the sequence returns True for that pair. If any of the rules returns True, then the pair is blocked (dropped).
- Parameters
candset (DataFrame) – The input candidate set of tuple pairs.
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_jobs (int) – The number of parallel jobs to be used for computation (defaults to 1). If -1 all CPUs are used. If 0 or 1, no parallel computation is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used (where n_cpus are the total number of CPUs in the machine).Thus, for n_jobs = -2, all CPUs but one are used. If (n_cpus + 1 + n_jobs) is less than 1, then no parallel computation is used (i.e., equivalent to the default).
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If candset is not of type pandas DataFrame.
AssertionError – If verbose is not of type boolean.
AssertionError – If n_jobs is not of type int.
AssertionError – If show_progress is not of type boolean.
AssertionError – If l_block_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
AssertionError – If there are no rules to apply.
Examples
>>> import py_entitymatching as em >>> rb = em.RuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, feature_table=block_f) >>> D = rb.block_tables(C) # C is the candidate set.
-
block_tables(ltable, rtable, l_output_attrs=None, r_output_attrs=None, l_output_prefix='ltable_', r_output_prefix='rtable_', verbose=False, show_progress=True, n_jobs=1)¶ Blocks two tables based on the sequence of rules supplied by the user.
Finds tuple pairs from left and right tables that survive the sequence of blocking rules. A tuple pair survives the sequence of blocking rules if none of the rules in the sequence returns True for that pair. If any of the rules returns True, then the pair is blocked.
- Parameters
ltable (DataFrame) – The left input table.
rtable (DataFrame) – The right input table.
l_output_attrs (list) – A list of attribute names from the left table to be included in the output candidate set (defaults to None).
r_output_attrs (list) – A list of attribute names from the right table to be included in the output candidate set (defaults to None).
l_output_prefix (string) – The prefix to be used for the attribute names coming from the left table in the output candidate set (defaults to ‘ltable_’).
r_output_prefix (string) – The prefix to be used for the attribute names coming from the right table in the output candidate set (defaults to ‘rtable_’).
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_jobs (int) – The number of parallel jobs to be used for computation (defaults to 1). If -1 all CPUs are used. If 0 or 1, no parallel computation is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used (where n_cpus is the total number of CPUs in the machine).Thus, for n_jobs = -2, all CPUs but one are used. If (n_cpus + 1 + n_jobs) is less than 1, then no parallel computation is used (i.e., equivalent to the default).
- Returns
A candidate set of tuple pairs that survived the sequence of blocking rules (DataFrame).
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
AssertionError – If l_output_attrs is not of type of list.
AssertionError – If r_output_attrs is not of type of list.
AssertionError – If the values in l_output_attrs is not of type string.
AssertionError – If the values in r_output_attrs is not of type string.
AssertionError – If the input l_output_prefix is not of type string.
AssertionError – If the input r_output_prefix is not of type string.
AssertionError – If verbose is not of type boolean.
AssertionError – If show_progress is not of type boolean.
AssertionError – If n_jobs is not of type int.
AssertionError – If l_out_attrs are not in the ltable.
AssertionError – If r_out_attrs are not in the rtable.
AssertionError – If there are no rules to apply.
Examples
>>> import py_entitymatching as em >>> rb = em.RuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, feature_table=block_f) >>> C = rb.block_tables(A, B)
-
block_tuples(ltuple, rtuple)¶ Blocks a tuple pair based on a sequence of blocking rules supplied by the user.
- Parameters
ltuple (Series) – The input left tuple.
rtuple (Series) – The input right tuple.
- Returns
A status indicating if the tuple pair is blocked by applying the sequence of blocking rules (boolean).
Examples
>>> import py_entitymatching as em >>> rb = em.RuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, feature_table=block_f) >>> D = rb.block_tuples(A.ix[0], B.ix[1)
-
delete_rule(rule_name)¶ Deletes a rule from the rule-based blocker.
- Parameters
rule_name (string) – Name of the rule to be deleted.
Examples
>>> import py_entitymatching as em >>> rb = em.RuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, block_f, rule_name='rule_1') >>> rb.delete_rule('rule_1')
-
get_rule(rule_name)¶ Returns the function corresponding to a rule.
- Parameters
rule_name (string) – Name of the rule.
- Returns
A function object corresponding to the specified rule.
Examples
>>> import py_entitymatching as em >>> rb = em.RuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, feature_table=block_f, rule_name='rule_1') >>> rb.get_rule()
-
get_rule_names()¶ Returns the names of all the rules in the rule-based blocker.
- Returns
A list of names of all the rules in the rule-based blocker (list).
Examples
>>> import py_entitymatching as em >>> rb = em.RuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, block_f, rule_name='rule_1') >>> rb.get_rule_names()
-
set_feature_table(feature_table)¶ Sets feature table for the rule-based blocker.
- Parameters
feature_table (DataFrame) – A DataFrame containing features.
Examples
>>> import py_entitymatching as em >>> rb = em.RuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rb.set_feature_table(block_f)
-
view_rule(rule_name)¶ Prints the source code of the function corresponding to a rule.
- Parameters
rule_name (string) – Name of the rule to be viewed.
Examples
>>> import py_entitymatching as em >>> rb = em.RuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, block_f, rule_name='rule_1') >>> rb.view_rule('rule_1')
-
-
class
py_entitymatching.BlackBoxBlocker(*args, **kwargs)¶ Blocks based on a black box function specified by the user.
-
block_candset(candset, verbose=True, show_progress=True, n_jobs=1)¶ Blocks an input candidate set of tuple pairs based on a black box blocking function specified by the user.
Finds tuple pairs from an input candidate set of tuple pairs that survive the black box function. A tuple pair survives the black box blocking function if the function returns False for that pair, otherwise the tuple pair is dropped.
- Parameters
candset (DataFrame) – The input candidate set of tuple pairs.
verbose (boolean) – A flag to indicate whether logging should be done (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_jobs (int) – The number of parallel jobs to be used for computation (defaults to 1). If -1 all CPUs are used. If 0 or 1, no parallel computation is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used (where n_cpus is the total number of CPUs in the machine).Thus, for n_jobs = -2, all CPUs but one are used. If (n_cpus + 1 + n_jobs) is less than 1, then no parallel computation is used (i.e., equivalent to the default).
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If candset is not of type pandas DataFrame.
AssertionError – If verbose is not of type boolean.
AssertionError – If n_jobs is not of type int.
AssertionError – If show_progress is not of type boolean.
AssertionError – If l_block_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
Examples
>>> def match_last_name(ltuple, rtuple): # assume that there is a 'name' attribute in the input tables # and each value in it has two words l_last_name = ltuple['name'].split()[1] r_last_name = rtuple['name'].split()[1] if l_last_name != r_last_name: return True else: return False >>> import py_entitymatching as em >>> bb = em.BlackBoxBlocker() >>> bb.set_black_box_function(match_last_name) >>> D = bb.block_candset(C) # C is an output from block_tables
-
block_tables(ltable, rtable, l_output_attrs=None, r_output_attrs=None, l_output_prefix='ltable_', r_output_prefix='rtable_', verbose=False, show_progress=True, n_jobs=1)¶ Blocks two tables based on a black box blocking function specified by the user.
Finds tuple pairs from left and right tables that survive the black box function. A tuple pair survives the black box blocking function if the function returns False for that pair, otherwise the tuple pair is dropped.
- Parameters
ltable (DataFrame) – The left input table.
rtable (DataFrame) – The right input table.
l_output_attrs (list) – A list of attribute names from the left table to be included in the output candidate set (defaults to None).
r_output_attrs (list) – A list of attribute names from the right table to be included in the output candidate set (defaults to None).
l_output_prefix (string) – The prefix to be used for the attribute names coming from the left table in the output candidate set (defaults to ‘ltable_’).
r_output_prefix (string) – The prefix to be used for the attribute names coming from the right table in the output candidate set (defaults to ‘rtable_’).
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_jobs (int) – The number of parallel jobs to be used for computation (defaults to 1). If -1 all CPUs are used. If 0 or 1, no parallel computation is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used (where n_cpus are the total number of CPUs in the machine).Thus, for n_jobs = -2, all CPUs but one are used. If (n_cpus + 1 + n_jobs) is less than 1, then no parallel computation is used (i.e., equivalent to the default).
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
AssertionError – If l_output_attrs is not of type of list.
AssertionError – If r_output_attrs is not of type of list.
AssertionError – If values in l_output_attrs is not of type string.
AssertionError – If values in r_output_attrs is not of type string.
AssertionError – If l_output_prefix is not of type string.
AssertionError – If r_output_prefix is not of type string.
AssertionError – If verbose is not of type boolean.
AssertionError – If show_progress is not of type boolean.
AssertionError – If n_jobs is not of type int.
AssertionError – If l_out_attrs are not in the ltable.
AssertionError – If r_out_attrs are not in the rtable.
Examples
>>> def match_last_name(ltuple, rtuple): # assume that there is a 'name' attribute in the input tables # and each value in it has two words l_last_name = ltuple['name'].split()[1] r_last_name = rtuple['name'].split()[1] if l_last_name != r_last_name: return True else: return False >>> import py_entitymatching as em >>> bb = em.BlackBoxBlocker() >>> bb.set_black_box_function(match_last_name)
>>> C = bb.block_tables(A, B, l_output_attrs=['name'], r_output_attrs=['name'] )
-
block_tuples(ltuple, rtuple)¶ Blocks a tuple pair based on a black box blocking function specified by the user.
Takes a tuple pair as input, applies the black box blocking function to it, and returns True (if the intention is to drop the pair) or False (if the intention is to keep the tuple pair).
- Parameters
ltuple (Series) – input left tuple.
rtuple (Series) – input right tuple.
- Returns
A status indicating if the tuple pair should be dropped or kept, based on the black box blocking function (boolean).
Examples
>>> def match_last_name(ltuple, rtuple): # assume that there is a 'name' attribute in the input tables # and each value in it has two words l_last_name = ltuple['name'].split()[1] r_last_name = rtuple['name'].split()[1] if l_last_name != r_last_name: return True else: return False >>> import py_entitymatching as em >>> bb = em.BlackBoxBlocker() >>> bb.set_black_box_function(match_last_name) >>> status = bb.block_tuples(A.ix[0], B.ix[0]) # A, B are input tables.
-
set_black_box_function(function)¶ Sets black box function to be used for blocking.
- Parameters
function (function) – the black box function to be used for blocking .
-
-
class
py_entitymatching.SortedNeighborhoodBlocker¶ WARNING: THIS IS AN EXPERIMENTAL CLASS. THIS CLASS IS NOT TESTED. USE AT YOUR OWN RISK.
Blocks based on the sorted neighborhood blocking method
-
static
block_candset(*args, **kwargs)¶ block_candset does not apply to sn_blocker, return unimplemented
-
block_tables(ltable, rtable, l_block_attr, r_block_attr, window_size=2, l_output_attrs=None, r_output_attrs=None, l_output_prefix='ltable_', r_output_prefix='rtable_', allow_missing=False, verbose=False, n_jobs=1)¶ WARNING: THIS IS AN EXPERIMENTAL COMMAND. THIS COMMAND IS NOT TESTED. USE AT YOUR OWN RISK.
Blocks two tables based on sorted neighborhood.
Finds tuple pairs from left and right tables such that when each table is sorted based upon a blocking attribute, tuple pairs are within a distance w of each other. The blocking attribute is created prior to calling this function.
- Parameters
ltable (DataFrame) – The left input table.
rtable (DataFrame) – The right input table.
l_block_attr (string) – The blocking attribute for left table.
r_block_attr (string) – The blocking attribute for right table.
window_size (int) – size of sliding window. Defaults to 2
l_output_attrs (list) – A list of attribute names from the left table to be included in the output candidate set (defaults to None).
r_output_attrs (list) – A list of attribute names from the right table to be included in the output candidate set (defaults to None).
l_output_prefix (string) – The prefix to be used for the attribute names coming from the left table in the output candidate set (defaults to ‘ltable_’).
r_output_prefix (string) – The prefix to be used for the attribute names coming from the right table in the output candidate set (defaults to ‘rtable_’).
allow_missing (boolean) – A flag to indicate whether tuple pairs with missing value in at least one of the blocking attributes should be included in the output candidate set (defaults to False). If this flag is set to True, a tuple in ltable with missing value in the blocking attribute will be matched with every tuple in rtable and vice versa.
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
n_jobs (int) – The number of parallel jobs to be used for computation (defaults to 1). If -1 all CPUs are used. If 0 or 1, no parallel computation is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used (where n_cpus is the total number of CPUs in the machine). Thus, for n_jobs = -2, all CPUs but one are used. If (n_cpus + 1 + n_jobs) is less than 1, then no parallel computation is used (i.e., equivalent to the default).
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
AssertionError – If l_block_attr is not of type string.
AssertionError – If r_block_attr is not of type string.
AssertionError – If window_size is not of type of int or if window_size < 2.
AssertionError – If the values in l_output_attrs is not of type string.
AssertionError – If the values in r_output_attrs is not of type string.
AssertionError – If l_output_prefix is not of type string.
AssertionError – If r_output_prefix is not of type string.
AssertionError – If verbose is not of type boolean.
AssertionError – If allow_missing is not of type boolean.
AssertionError – If n_jobs is not of type int.
AssertionError – If l_block_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
AssertionError – If l_out_attrs are not in the ltable.
AssertionError – If r_out_attrs are not in the rtable.
-
static
block_tuples(*args, **kwargs)¶ block_tuples does not apply to sn_blocker, return unimplemented
-
static
validate_block_attrs(ltable, rtable, l_block_attr, r_block_attr)¶ validate the blocking attributes
-
static
validate_types_block_attrs(l_block_attr, r_block_attr)¶ validate the data types of the blocking attributes
-
static
Debugging Blocker Output¶
-
py_entitymatching.debug_blocker(candidate_set, ltable, rtable, output_size=200, attr_corres=None, verbose=True, n_jobs=1, n_configs=1)¶ This function debugs the blocker output and reports a list of potential matches that are discarded by a blocker (or a blocker sequence). Specifically, this function takes in the two input tables for matching and the candidate set returned by a blocker (or a blocker sequence), and produces a list of tuple pairs which are rejected by the blocker but with high potential of being true matches.
- Parameters
candidate_set (DataFrame) – The candidate set generated by applying the blocker on the ltable and rtable.
ltable,rtable (DataFrame) – The input DataFrames that are used to generate the blocker output.
output_size (int) – The number of tuple pairs that will be returned (defaults to 200).
attr_corres (list) – A list of attribute correspondence tuples. When ltable and rtable have different schemas, or the same schema but different words describing the attributes, the user needs to manually specify the attribute correspondence. Each element in this list should be a tuple of strings which are the corresponding attributes in ltable and rtable. The default value is None, and if the user doesn’t specify this list, a built-in function for finding the attribute correspondence list will be called. But we highly recommend the users manually specify the attribute correspondences, unless the schemas of ltable and rtable are identical (defaults to None).
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
n_jobs (int) – The number of parallel jobs to be used for computation (defaults to 1). If -1 all CPUs are used. If 0 or 1, no parallel computation is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used (where n_cpus are the total number of CPUs in the machine).Thus, for n_jobs = -2, all CPUs but one are used. If (n_cpus + 1 + n_jobs) is less than 1, then no parallel computation is used (i.e., equivalent to the default).
n_configs (int) – The maximum number of configs to be used for calculating the topk list(defaults to 1). If -1, the config number is set as the number of cpu. If -2, all configs are used. if n_configs is less than the maximum number of generated configs, then n_configs will be used. Otherwise, all the generated configs will be used.
- Returns
A pandas DataFrame with ‘output_size’ number of rows. Each row in the DataFrame is a tuple pair which has potential of being a true match, but is rejected by the blocker (meaning that the tuple pair is in the Cartesian product of ltable and rtable subtracted by the candidate set). The fields in the returned DataFrame are from ltable and rtable, which are useful for determining similar tuple pairs.
- Raises
AssertionError – If ltable, rtable or candset is not of type pandas DataFrame.
AssertionError – If ltable or rtable is empty (size of 0).
AssertionError – If the output size parameter is less than or equal to 0.
AssertionError – If the attribute correspondence (attr_corres) list is not in the correct format (a list of tuples).
AssertionError – If the attribute correspondence (attr_corres) cannot be built correctly.
Examples
>>> import py_entitymatching as em >>> ob = em.OverlapBlocker() >>> C = ob.block_tables(A, B, l_overlap_attr='title', r_overlap_attr='title', overlap_size=3) >>> corres = [('ID','ssn'), ('name', 'ename'), ('address', 'location'),('zipcode', 'zipcode')] >>> D = em.debug_blocker(C, A, B, attr_corres=corres) >>> import py_entitymatching as em >>> ob = em.OverlapBlocker() >>> C = ob.block_tables(A, B, l_overlap_attr='name', r_overlap_attr='name', overlap_size=3) >>> D = em.debug_blocker(C, A, B, output_size=150)
-
py_entitymatching.backup_debug_blocker(candset, ltable, rtable, output_size=200, attr_corres=None, verbose=False)¶ This is the old version of the blocker debugger. It is not reccomended to use this version unless the new blocker debugger is not working properly.
This function debugs the blocker output and reports a list of potential matches that are discarded by a blocker (or a blocker sequence).
Specifically, this function takes in the two input tables for matching and the candidate set returned by a blocker (or a blocker sequence), and produces a list of tuple pairs which are rejected by the blocker but with high potential of being true matches.
- Parameters
candset (DataFrame) – The candidate set generated by applying the blocker on the ltable and rtable.
ltable,rtable (DataFrame) – The input DataFrames that are used to generate the blocker output.
output_size (int) – The number of tuple pairs that will be returned (defaults to 200).
attr_corres (list) – A list of attribute correspondence tuples. When ltable and rtable have different schemas, or the same schema but different words describing the attributes, the user needs to manually specify the attribute correspondence. Each element in this list should be a tuple of strings which are the corresponding attributes in ltable and rtable. The default value is None, and if the user doesn’t specify this list, a built-in function for finding the attribute correspondence list will be called. But we highly recommend the users manually specify the attribute correspondences, unless the schemas of ltable and rtable are identical (defaults to None).
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
- Returns
A pandas DataFrame with ‘output_size’ number of rows. Each row in the DataFrame is a tuple pair which has potential of being a true match, but is rejected by the blocker (meaning that the tuple pair is in the Cartesian product of ltable and rtable subtracted by the candidate set). The fields in the returned DataFrame are from ltable and rtable, which are useful for determining similar tuple pairs.
- Raises
AssertionError – If ltable, rtable or candset is not of type pandas DataFrame.
AssertionError – If ltable or rtable is empty (size of 0).
AssertionError – If the output size parameter is less than or equal to 0.
AssertionError – If the attribute correspondence (attr_corres) list is not in the correct format (a list of tuples).
AssertionError – If the attribute correspondence (attr_corres) cannot be built correctly.
Examples
>>> import py_entitymatching as em >>> ob = em.OverlapBlocker() >>> C = ob.block_tables(A, B, l_overlap_attr='title', r_overlap_attr='title', overlap_size=3) >>> corres = [('ID','ssn'), ('name', 'ename'), ('address', 'location'),('zipcode', 'zipcode')] >>> D = em.backup_debug_blocker(C, A, B, attr_corres=corres)
>>> import py_entitymatching as em >>> ob = em.OverlapBlocker() >>> C = ob.block_tables(A, B, l_overlap_attr='name', r_overlap_attr='name', overlap_size=3) >>> D = em.backup_debug_blocker(C, A, B, output_size=150)
Combining Blocker Outputs¶
-
py_entitymatching.combine_blocker_outputs_via_union(blocker_output_list, l_prefix='ltable_', r_prefix='rtable_', verbose=False)¶ Combines multiple blocker outputs by doing a union of their tuple pair ids (foreign key ltable, foreign key rtable).
Specifically, this function takes in a list of DataFrames (candidate sets, typically the output from blockers) and returns a consolidated DataFrame. The output DataFrame contains the union of tuple pair ids (foreign key ltable, foreign key rtable) and other attributes from the input list of DataFrames.
This function makes some assumptions about the input DataFrames. First, each DataFrame is expected to contain the following metadata in the catalog: key, fk_ltable, fk_rtable, ltable, and rtable. Second, all the DataFrames must be a result of blocking from the same underlying tables. Concretely the ltable and rtable properties must refer to the same DataFrame across all the input tables. Third, all the input DataFrames must have the same fk_ltable and fk_rtable properties. Finally, in each input DataFrame, for the attributes included from the ltable or rtable, the attribute names must be prefixed with the given l_prefix and r_prefix in the function.
The input DataFrames may contain different attribute lists and it demands the question of how to combine them. Currently py_entitymatching takes an union of attribute names that has prefix l_prefix or r_prefix across input tables. After taking the union, for each tuple id pair included in output, the attribute values (for union-ed attribute names) are probed from ltable/rtable and included in the output.
A subtle point to note here is, if an input DataFrame has a column added by user (say label for some reason), then that column will not be present in the output. The reason is, the same column may not be present in other candidate sets so it is not clear about how to combine them. One possibility is to include label in output for all tuple id pairs, but set as NaN for the values not present. Currently py_entitymatching does not include such columns and addressing it will be part of future work.
- Parameters
blocker_output_list (list of DataFrames) – The list of DataFrames that should be combined.
l_prefix (string) – The prefix given to the attributes from the ltable.
r_prefix (string) – The prefix given to the attributes from the rtable.
verbose (boolean) – A flag to indicate whether more detailed information about the execution steps should be printed out (default value is False).
- Returns
A new DataFrame with the combined tuple pairs and other attributes from all the blocker lists.
- Raises
AssertionError – If l_prefix is not of type string.
AssertionError – If r_prefix is not of type string.
AssertionError – If the length of the input DataFrame list is 0.
AssertionError – If blocker_output_list is not a list of DataFrames.
AssertionError – If the ltables are different across the input list of DataFrames.
AssertionError – If the rtables are different across the input list of DataFrames.
AssertionError – If the fk_ltable values are different across the input list of DataFrames.
AssertionError – If the fk_rtable values are different across the input list of DataFrames.
Examples
>>> import py_entitymatching as em >>> ab = em.AttrEquivalenceBlocker() >>> C = ab.block_tables(A, B, 'zipcode', 'zipcode') >>> ob = em.OverlapBlocker() >>> D = ob.block_candset(C, 'address', 'address') >>> block_f = em.get_features_for_blocking(A, B) >>> rb = em.RuleBasedBlocker() >>> rule = ['address_address_lev(ltuple, rtuple) > 6'] >>> rb.add_rule(rule, block_f) >>> E = rb.block_tables(A, B) >>> F = em.combine_blocker_outputs_via_union([C, E])
Sampling¶
-
py_entitymatching.sample_table(table, sample_size, replace=False, verbose=False)¶ Samples a candidate set of tuple pairs (for labeling purposes).
This function samples a DataFrame, typically used for labeling purposes. This function expects the input DataFrame containing the metadata of a candidate set (such as key, fk_ltable, fk_rtable, ltable, rtable). Specifically, this function creates a copy of the input DataFrame, samples the data using uniform random sampling (uses ‘random’ function from numpy to sample) and returns the sampled DataFrame. Further, also copies the properties from the input DataFrame to the output DataFrame.
- Parameters
table (DataFrame) – The input DataFrame to be sampled. Specifically, a DataFrame containing the metadata of a candidate set (such as key, fk_ltable, fk_rtable, ltable, rtable) in the catalog.
sample_size (int) – The number of samples to be picked from the input DataFrame.
replace (boolean) – A flag to indicate whether sampling should be done with replacement or not (defaults to False).
verbose (boolean) – A flag to indicate whether more detailed information about the execution steps should be printed out (defaults to False).
- Returns
A new DataFrame with ‘sample_size’ number of rows.
Further, this function sets the output DataFrame’s properties same as input DataFrame.
- Raises
AssertionError – If table is not of type pandas DataFrame.
AssertionError – If the size of table is 0.
AssertionError – If the sample_size is greater than the input DataFrame size.
Examples
>>> import py_entitymatching as em >>> S = em.sample_table(C, sample_size=450) # C is the candidate set to be sampled from.
Note
As mentioned in the above description, the output DataFrame is updated (in the catalog) with the properties from the input DataFrame. A subtle point to note here is, when the replace flag is set to True, then the output DataFrame can contain duplicate keys. In that case, this function will not set the key and it is up to the user to fix it after the function returns.
Labeling¶
-
py_entitymatching.label_table(table, label_column_name, verbose=False)¶ Label a pandas DataFrame (for supervised learning purposes).
This functions labels a DataFrame, typically used for supervised learning purposes. This function expects the input DataFrame containing the metadata of a candidate set (such as key, fk_ltable, fk_rtable, ltable, rtable). This function creates a copy of the input DataFrame, adds label column at the end of the DataFrame, fills the column values with 0, invokes a GUI for the user to enter labels (0/1, 0: non-match, 1: match) and finally returns the labeled DataFrame. Further, this function also copies the properties from the input DataFrame to the output DataFrame.
- Parameters
table (DataFrame) – The input DataFrame to be labeled. Specifically, a DataFrame containing the metadata of a candidate set (such as key, fk_ltable, fk_rtable, ltable, rtable) in the catalog.
label_column_name (string) – The column name to be given for the labels entered by the user.
verbose (boolean) – A flag to indicate whether more detailed information about the execution steps should be printed out (default value is False).
- Returns
A new DataFrame with the labels entered by the user. Further, this function sets the output DataFrame’s properties same as input DataFrame.
- Raises
AssertionError – If table is not of type pandas DataFrame.
AssertionError – If label_column_name is not of type string.
AssertionError – If the label_column_name is already present in the input table.
Examples
>>> import py_entitymatching as em >>> G = em.label_table(S, label_column_name='label') # S is the (sampled) table that has to be labeled.
Handling Features¶
Creating the Features Automatically¶
-
py_entitymatching.get_features_for_blocking(ltable, rtable, validate_inferred_attr_types=True)¶ This function automatically generates features that can be used for blocking purposes.
- Parameters
ltable,rtable (DataFrame) – The pandas DataFrames for which the features are to be generated.
validate_inferred_attr_types (boolean) – A flag to indicate whether to show the user the inferred attribute types and the features chosen for those types.
- Returns
A pandas DataFrame containing automatically generated features.
Specifically, the DataFrame contains the following attributes: ‘feature_name’, ‘left_attribute’, ‘right_attribute’, ‘left_attr_tokenizer’, ‘right_attr_tokenizer’, ‘simfunction’, ‘function’, ‘function_source’, and ‘is_auto_generated’.
Further, this function also sets the following global variables: _block_t, _block_s, _atypes1, _atypes2, and _block_c.
The variable _block_t contains the tokenizers used and _block_s contains the similarity functions used for creating features.
The variables _atypes1, and _atypes2 contain the attribute types for ltable and rtable respectively. The variable _block_c contains the attribute correspondences between the two input tables.
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
AssertionError – If validate_inferred_attr_types is not of type pandas DataFrame.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> block_f = em.get_features_for_blocking(A, B)
Note
In the output DataFrame, two attributes demand some explanation: (1) function, and (2) is_auto_generated. The function, points to the actual Python function that implements the feature. Specifically, the function takes in two tuples (one from each input table) and returns a numeric value. The attribute is_auto_generated contains either True or False. The flag is True only if the feature is automatically generated by py_entitymatching. This is important because this flag is used to make some assumptions about the semantics of the similarity function used and use that information for scaling purposes.
-
py_entitymatching.get_features_for_matching(ltable, rtable, validate_inferred_attr_types=True)¶ This function automatically generates features that can be used for matching purposes.
- Parameters
ltable,rtable (DataFrame) – The pandas DataFrames for which the features are to be generated.
validate_inferred_attr_types (boolean) – A flag to indicate whether to show the user the inferred attribute types and the features chosen for those types.
- Returns
A pandas DataFrame containing automatically generated features.
Specifically, the DataFrame contains the following attributes: ‘feature_name’, ‘left_attribute’, ‘right_attribute’, ‘left_attr_tokenizer’, ‘right_attr_tokenizer’, ‘simfunction’, ‘function’, ‘function_source’, and ‘is_auto_generated’.
Further, this function also sets the following global variables: _match_t, _match_s, _atypes1, _atypes2, and _match_c.
The variable _match_t contains the tokenizers used and _match_s contains the similarity functions used for creating features.
The variables _atypes1, and _atypes2 contain the attribute types for ltable and rtable respectively. The variable _match_c contains the attribute correspondences between the two input tables.
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
AssertionError – If validate_inferred_attr_types is not of type pandas DataFrame.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> match_f = em.get_features_for_matching(A, B)
Note
In the output DataFrame, two attributes demand some explanation: (1) function, and (2) is_auto_generated. The function, points to the actual Python function that implements the feature. Specifically, the function takes in two tuples (one from each input table) and returns a numeric value. The attribute is_auto_generated contains either True or False. The flag is True only if the feature is automatically generated by py_entitymatching. This is important because this flag is used to make some assumptions about the semantics of the similarity function used and use that information for scaling purposes.
Creating the Features Manually¶
-
py_entitymatching.get_features(ltable, rtable, l_attr_types, r_attr_types, attr_corres, tok_funcs, sim_funcs)¶ This function will automatically generate a set of features based on the attributes of the input tables.
Specifically, this function will go through the attribute correspondences between the input tables. For each correspondence , it examines the types of the involved attributes, then apply the appropriate tokenizers and sim functions to generate all appropriate features for this correspondence.
- Parameters
ltable,rtable (DataFrame) – The pandas DataFrames for which the features must be generated.
l_attr_types,r_attr_types (dictionary) – The attribute types for the input DataFrames. Typically this is generated using the function ‘get_attr_types’.
attr_corres (dictionary) – The attribute correspondences between the input DataFrames.
tok_funcs (dictionary) – A Python dictionary containing tokenizer functions.
sim_funcs (dictionary) – A Python dictionary containing similarity functions.
- Returns
A pandas DataFrame containing automatically generated features. Specifically, the DataFrame contains the following attributes: ‘feature_name’, ‘left_attribute’, ‘right_attribute’, ‘left_attr_tokenizer’, ‘right_attr_tokenizer’, ‘simfunction’, ‘function’, ‘function_source’, ‘is_auto_generated’.
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
AssertionError – If l_attr_types is not of type python dictionary.
AssertionError – If r_attr_types is not of type python dictionary.
AssertionError – If attr_corres is not of type python dictionary.
AssertionError – If sim_funcs is not of type python dictionary.
AssertionError – If tok_funcs is not of type python dictionary.
AssertionError – If the ltable and rtable order is same as mentioned in the l_attr_types/r_attr_types and attr_corres.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> match_t = em.get_tokenizers_for_matching() >>> match_s = em.get_sim_funs_for_matching() >>> atypes1 = em.get_attr_types(A) # don't need, if atypes1 exists from blocking step >>> atypes2 = em.get_attr_types(B) # don't need, if atypes2 exists from blocking step >>> match_c = em.get_attr_corres(A, B) >>> match_f = em.get_features(A, B, atypes1, atype2, match_c, match_t, match_s)
See also
py_entitymatching.get_attr_corres(),py_entitymatching.get_attr_types(),py_entitymatching.get_sim_funs_for_blocking(),py_entitymatching.get_tokenizers_for_blocking(),py_entitymatching.get_sim_funs_for_matching(),py_entitymatching.get_tokenizers_for_matching()Note
In the output DataFrame, two attributes demand some explanation: (1)function, and (2) is_auto_generated. The function, points to the actual python function that implements feature. Specifically, the function takes in two tuples (one from each input table) and returns a numeric value. The attribute is_auto_generated contains either True or False. The flag is True only if the feature is automatically generated by py_entitymatching. This is important because this flag is used to make some assumptions about the semantics of the similarity function used and use that information for scaling purposes.
-
py_entitymatching.get_attr_corres(ltable, rtable)¶ This function gets the attribute correspondences between the attributes of ltable and rtable.
The user may need to get the correspondences so that he/she can generate features based those correspondences.
- Parameters
ltable,rtable (DataFrame) – Input DataFrames for which the attribute correspondences must be obtained.
- Returns
A Python dictionary is returned containing the attribute correspondences.
Specifically, this returns a dictionary with the following key-value pairs:
corres: points to the list correspondences as tuples. Each correspondence is a tuple with two attributes: one from ltable and the other from rtable.
ltable: points to ltable.
rtable: points to rtable.
Currently, ‘corres’ contains only pairs of attributes with exact names in ltable and rtable.
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> match_c = em.get_attr_corres(A, B)
-
py_entitymatching.get_attr_types(data_frame)¶ This function gets the attribute types for a DataFrame.
Specifically this function gets the attribute types based on the statistics of the attributes. These attribute types can be str_eq_1w, str_bt_1w_5w, str_bt_5w_10w, str_gt_10w, boolean or numeric.
The types roughly capture whether the attribute is of type string, boolean or numeric. Further, with in the string type the subtypes are capture the average number of tokens in the column values. For example, str_bt_1w_5w means the average number of tokens in that column is greater than one word but less than 5 words.
- Parameters
data_frame (DataFrame) – The input DataFrame for which types of attributes must be determined.
- Returns
A Python dictionary is returned containing the attribute types.
Specifically, in the dictionary key is an attribute name, value is the type of that attribute.
Further, the dictionary will have a key _table, and the value of that should be a pointer to the input DataFrame.
- Raises
AssertionError – If data_frame is not of type pandas DataFrame.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> atypes1 = em.get_attr_types(A) >>> atypes2 = em.get_attr_types(B)
-
py_entitymatching.get_sim_funs_for_blocking()¶ This function returns the similarity functions that can be used for blocking purposes.
- Returns
A Python dictionary containing the similarity functions.
Specifically, the key is the similarity function name and the value is the actual similary function.
Examples
>>> import py_entitymatching as em >>> block_s = em.get_sim_funs_for_blocking()
-
py_entitymatching.get_sim_funs_for_matching()¶ This function returns the similarity functions that can be used for matching purposes.
- Returns
A Python dictionary containing the similarity functions.
Specifically, the key is the similarity function name and the value is the actual similarity function.
Examples
>>> import py_entitymatching as em >>> match_s = em.get_sim_funs_for_matching()
-
py_entitymatching.get_tokenizers_for_blocking(q=[2, 3], dlm_char=[' '])¶ This function returns the single argument tokenizers that can be used for blocking purposes (typically in rule-based blocking).
- Parameters
q (list) – The list of integers (i.e q value) for which the q-gram tokenizer must be generated (defaults to [2, 3]).
dlm_char (list) – The list of characters (i.e delimiter character) for which the delimiter tokenizer must be generated (defaults to [` ‘]).
- Returns
A Python dictionary with tokenizer name as the key and tokenizer function as the value.
- Raises
AssertionError – If both q and dlm_char are set to None.
Examples
>>> import py_entitymatching as em >>> block_t = em.get_tokenizers_for_blocking() >>> block_t = em.get_tokenizers_for_blocking(q=[3], dlm_char=None) >>> block_t = em.get_tokenizers_for_blocking(q=None, dlm_char=[' '])
-
py_entitymatching.get_tokenizers_for_matching(q=[2, 3], dlm_char=[' '])¶ This function returns the single argument tokenizers that can be used for matching purposes.
- Parameters
q (list) – The list of integers (i.e q value) for which the q-gram tokenizer must be generated (defaults to [2, 3]).
dlm_char (list) – The list of characters (i.e delimiter character) for which the delimiter tokenizer must be generated (defaults to [` ‘]).
- Returns
A Python dictionary with tokenizer name as the key and tokenizer function as the value.
- Raises
AssertionError – If both q and dlm_char are set to None.
Examples
>>> import py_entitymatching as em >>> match_t = em.get_tokenizers_for_blocking() >>> match_t = em.get_tokenizers_for_blocking(q=[3], dlm_char=None) >>> match_t = em.get_tokenizers_for_blocking(q=None, dlm_char=[' '])
Adding Features to Feature Table¶
-
py_entitymatching.get_feature_fn(feature_string, tokenizers, similarity_functions)¶ This function creates a feature in a declarative manner.
Specifically, this function uses the feature string, parses it and compiles it into a function using the given tokenizers and similarity functions. This compiled function will take in two tuples and return a feature value (typically a number).
- Parameters
feature_string (string) – A feature expression to be converted into a function.
tokenizers (dictionary) – A Python dictionary containing tokenizers. Specifically, the dictionary contains tokenizer names as keys and tokenizer functions as values. The tokenizer function typically takes in a string and returns a list of tokens.
similarity_functions (dictionary) – A Python dictionary containing similarity functions. Specifically, the dictionary contains similarity function names as keys and similarity functions as values. The similarity function typically takes in a string or two lists of tokens and returns a number.
- Returns
This function returns a Python dictionary which contains sufficient information (such as attributes, tokenizers, function code) to be added to the feature table.
Specifically the Python dictionary contains the following keys: ‘left_attribute’, ‘right_attribute’, ‘left_attr_tokenizer’, ‘right_attr_tokenizer’, ‘simfunction’, ‘function’, and ‘function_source’.
For all the keys except the ‘function’ and ‘function_source’ the value will be either a valid string (if the input feature string is parsed correctly) or PARSE_EXP (if the parsing was not successful). The ‘function’ will have a valid Python function as value, and ‘function_source’ will have the Python function’s source in string format.
The created function is a self-contained function which means that the tokenizers and sim functions that it calls are bundled along with the returned function code.
- Raises
AssertionError – If feature_string is not of type string.
AssertionError – If the input tokenizers is not of type dictionary.
AssertionError – If the input similarity_functions is not of type dictionary.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID')
>>> block_t = em.get_tokenizers_for_blocking() >>> block_s = em.get_sim_funs_for_blocking() >>> block_f = em.get_features_for_blocking(A, B) >>> r = get_feature_fn('jaccard(qgm_3(ltuple.name), qgm_3(rtuple.name)', block_t, block_s) >>> em.add_feature(block_f, 'name_name_jac_qgm3_qgm3', r)
>>> match_t = em.get_tokenizers_for_matching() >>> match_s = em.get_sim_funs_for_matching() >>> match_f = em.get_features_for_matching(A, B) >>> r = get_feature_fn('jaccard(qgm_3(ltuple.name), qgm_3(rtuple.name)', match_t, match_s) >>> em.add_feature(match_f, 'name_name_jac_qgm3_qgm3', r)
-
py_entitymatching.add_feature(feature_table, feature_name, feature_dict)¶ Adds a feature to the feature table.
Specifically, this function is used in combination with
get_feature_fn(). First the user creates a dictionary usingget_feature_fn(), then the user uses this function to add feature_dict to the feature table.- Parameters
feature_table (DataFrame) – A DataFrame containing features.
feature_name (string) – The name that should be given to the feature.
feature_dict (dictionary) – A Python dictionary, that is typically returned by executing
get_feature_fn().
- Returns
A Boolean value of True is returned if the addition was successful.
- Raises
AssertionError – If the input feature_table is not of type pandas DataFrame.
AssertionError – If feature_name is not of type string.
AssertionError – If feature_dict is not of type Python dictionary.
AssertionError – If the feature_table does not have necessary columns such as ‘feature_name’, ‘left_attribute’, ‘right_attribute’, ‘left_attr_tokenizer’, ‘right_attr_tokenizer’, ‘simfunction’, ‘function’, and ‘function_source’ in the DataFrame.
AssertionError – If the feature_name is already present in the feature table.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID')
>>> block_t = em.get_tokenizers_for_blocking() >>> block_s = em.get_sim_funs_for_blocking() >>> block_f = em.get_features_for_blocking(A, B) >>> r = get_feature_fn('jaccard(qgm_3(ltuple.name), qgm_3(rtuple.name)', block_t, block_s) >>> em.add_feature(block_f, 'name_name_jac_qgm3_qgm3', r)
>>> match_t = em.get_tokenizers_for_matching() >>> match_s = em.get_sim_funs_for_matching() >>> match_f = em.get_features_for_matching(A, B) >>> r = get_feature_fn('jaccard(qgm_3(ltuple.name), qgm_3(rtuple.name)', match_t, match_s) >>> em.add_feature(match_f, 'name_name_jac_qgm3_qgm3', r)
-
py_entitymatching.add_blackbox_feature(feature_table, feature_name, feature_function)¶ Adds a black box feature to the feature table.
- Parameters
feature_table (DataFrame) – The input DataFrame (typically a feature table) to which the feature must be added.
feature_name (string) – The name that should be given to the feature.
feature_function (Python function) – A Python function for the black box feature.
- Returns
A Boolean value of True is returned if the addition was successful.
- Raises
AssertionError – If the input feature_table is not of type DataFrame.
AssertionError – If the input feature_name is not of type string.
AssertionError – If the feature_table does not have necessary columns such as ‘feature_name’, ‘left_attribute’, ‘right_attribute’, ‘left_attr_tokenizer’, ‘right_attr_tokenizer’, ‘simfunction’, ‘function’, and ‘function_source’ in the DataFrame.
AssertionError – If the feature_name is already present in the feature table.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> block_f = em.get_features_for_blocking(A, B) >>> def age_diff(ltuple, rtuple): >>> # assume that the tuples have age attribute and values are valid numbers. >>> return ltuple['age'] - rtuple['age'] >>> status = em.add_blackbox_feature(block_f, 'age_difference', age_diff)
Extracting Feature Vectors¶
-
py_entitymatching.extract_feature_vecs(candset, attrs_before=None, feature_table=None, attrs_after=None, verbose=False, show_progress=True, n_jobs=1)¶ This function extracts feature vectors from a DataFrame (typically a labeled candidate set).
Specifically, this function uses feature table, ltable and rtable (that is present in the candset’s metadata) to extract feature vectors.
- Parameters
candset (DataFrame) – The input candidate set for which the features vectors should be extracted.
attrs_before (list) – The list of attributes from the input candset, that should be added before the feature vectors (defaults to None).
feature_table (DataFrame) – A DataFrame containing a list of features that should be used to compute the feature vectors ( defaults to None).
attrs_after (list) – The list of attributes from the input candset that should be added after the feature vectors (defaults to None).
verbose (boolean) – A flag to indicate whether the debug information should be displayed (defaults to False).
show_progress (boolean) – A flag to indicate whether the progress of extracting feature vectors must be displayed (defaults to True).
- Returns
A pandas DataFrame containing feature vectors.
The DataFrame will have metadata ltable and rtable, pointing to the same ltable and rtable as the input candset.
Also, the output DataFrame will have three columns: key, foreign key ltable, foreign key rtable copied from input candset to the output DataFrame. These three columns precede the columns mentioned in attrs_before.
- Raises
AssertionError – If candset is not of type pandas DataFrame.
AssertionError – If attrs_before has attributes that are not present in the input candset.
AssertionError – If attrs_after has attribtues that are not present in the input candset.
AssertionError – If feature_table is set to None.
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> match_f = em.get_features_for_matching(A, B) >>> # G is the labeled dataframe which should be converted into feature vectors >>> H = em.extract_feature_vecs(G, features=match_f, attrs_before=['title'], attrs_after=['gold_labels'])
Imputing Missing Values¶
-
py_entitymatching.impute_table(table, exclude_attrs=None, missing_val='NaN', strategy='mean', axis=0, val_all_nans=0, verbose=True)¶ Impute table containing missing values.
- Parameters
table (DataFrame) – DataFrame which values should be imputed.
exclude_attrs (List) – list of attribute names to be excluded from imputing (defaults to None).
missing_val (string or int) – The placeholder for the missing values. All occurrences of missing_values will be imputed. For missing values encoded as np.nan, use the string value ‘NaN’ (defaults to ‘NaN’).
strategy (string) – String that specifies on how to impute values. Valid strings: ‘mean’, ‘median’, ‘most_frequent’ (defaults to ‘mean’).
axis (int) – axis=1 along rows, and axis=0 along columns (defaults to 0).
val_all_nans (float) – Value to fill in if all the values in the column are NaN.
- Returns
Imputed DataFrame.
- Raises
AssertionError – If table is not of type pandas DataFrame.
Examples
>>> import py_entitymatching as em >>> # H is the feature vector which should be imputed. Specifically, impute the missing values >>> # in each column, with the mean of that column >>> H = em.impute_table(H, exclude_attrs=['_id', 'ltable_id', 'rtable_id'], strategy='mean')
Supported Similarity Functions¶
-
py_entitymatching.affine(s1, s2)¶ This function computes the affine measure between the two input strings.
- Parameters
s1,s2 (string) – The input strings for which the similarity measure should be computed.
- Returns
The affine measure if both the strings are not missing (i.e NaN or None), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.affine('dva', 'deeva') 1.5 >>> em.affine(None, 'deeva') nan
-
py_entitymatching.hamming_dist(s1, s2)¶ This function computes the Hamming distance between the two input strings.
- Parameters
s1,s2 (string) – The input strings for which the similarity measure should be computed.
- Returns
The Hamming distance if both the strings are not missing (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.hamming_dist('alex', 'john') 4 >>> em.hamming_dist(None, 'john') nan
-
py_entitymatching.hamming_sim(s1, s2)¶ This function computes the Hamming similarity between the two input strings.
- Parameters
s1,s2 (string) – The input strings for which the similarity measure should be computed.
- Returns
The Hamming similarity if both the strings are not missing (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.hamming_sim('alex', 'alxe') 0.5 >>> em.hamming_sim(None, 'alex') nan
-
py_entitymatching.lev_dist(s1, s2)¶ This function computes the Levenshtein distance between the two input strings.
- Parameters
s1,s2 (string) – The input strings for which the similarity measure should be computed.
- Returns
The Levenshtein distance if both the strings are not missing (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.lev_dist('alex', 'alxe') 2 >>> em.lev_dist(None, 'alex') nan
-
py_entitymatching.lev_sim(s1, s2)¶ This function computes the Levenshtein similarity between the two input strings.
- Parameters
s1,s2 (string) – The input strings for which the similarity measure should be computed.
- Returns
The Levenshtein similarity if both the strings are not missing (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.lev_sim('alex', 'alxe') 0.5 >>> em.lev_dist(None, 'alex') nan
-
py_entitymatching.jaro(s1, s2)¶ This function computes the Jaro measure between the two input strings.
- Parameters
s1,s2 (string) – The input strings for which the similarity measure should be computed.
- Returns
The Jaro measure if both the strings are not missing (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.jaro('MARTHA', 'MARHTA') 0.9444444444444445 >>> em.jaro(None, 'MARTHA') nan
-
py_entitymatching.jaro_winkler(s1, s2)¶ This function computes the Jaro Winkler measure between the two input strings.
- Parameters
s1,s2 (string) – The input strings for which the similarity measure should be computed.
- Returns
The Jaro Winkler measure if both the strings are not missing (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.jaro_winkler('MARTHA', 'MARHTA') 0.9611111111111111 >>> >>> em.jaro_winkler('MARTHA', None) nan
-
py_entitymatching.needleman_wunsch(s1, s2)¶ This function computes the Needleman-Wunsch measure between the two input strings.
- Parameters
s1,s2 (string) – The input strings for which the similarity measure should be computed.
- Returns
The Needleman-Wunsch measure if both the strings are not missing (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.needleman_wunsch('dva', 'deeva') 1.0 >>> em.needleman_wunsch('dva', None) nan
-
py_entitymatching.smith_waterman(s1, s2)¶ This function computes the Smith-Waterman measure between the two input strings.
- Parameters
s1,s2 (string) – The input strings for which the similarity measure should be computed.
- Returns
The Smith-Waterman measure if both the strings are not missing (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.smith_waterman('cat', 'hat') 2.0 >>> em.smith_waterman('cat', None) nan
-
py_entitymatching.jaccard(arr1, arr2)¶ This function computes the Jaccard measure between the two input lists/sets.
- Parameters
arr1,arr2 (list or set) – The input list or sets for which the Jaccard measure should be computed.
- Returns
The Jaccard measure if both the lists/set are not None and do not have any missing tokens (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.jaccard(['data', 'science'], ['data']) 0.5 >>> em.jaccard(['data', 'science'], None) nan
-
py_entitymatching.cosine(arr1, arr2)¶ This function computes the cosine measure between the two input lists/sets.
- Parameters
arr1,arr2 (list or set) – The input list or sets for which the cosine measure should be computed.
- Returns
The cosine measure if both the lists/set are not None and do not have any missing tokens (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.cosine(['data', 'science'], ['data']) 0.7071067811865475 >>> em.cosine(['data', 'science'], None) nan
-
py_entitymatching.overlap_coeff(arr1, arr2)¶ This function computes the overlap coefficient between the two input lists/sets.
- Parameters
arr1,arr2 (list or set) – The input lists or sets for which the overlap coefficient should be computed.
- Returns
The overlap coefficient if both the lists/sets are not None and do not have any missing tokens (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.overlap_coeff(['data', 'science'], ['data']) 1.0 >>> em.overlap_coeff(['data', 'science'], None) nan
-
py_entitymatching.dice(arr1, arr2)¶ This function computes the Dice score between the two input lists/sets.
- Parameters
arr1,arr2 (list or set) – The input list or sets for which the Dice score should be computed.
- Returns
The Dice score if both the lists/set are not None and do not have any missing tokens (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.dice(['data', 'science'], ['data']) 0.6666666666666666 >>> em.dice(['data', 'science'], None) nan
-
py_entitymatching.monge_elkan(arr1, arr2)¶ This function computes the Monge-Elkan measure between the two input lists/sets. Specifically, this function uses Jaro-Winkler measure as the secondary function to compute the similarity score.
- Parameters
arr1,arr2 (list or set) – The input list or sets for which the Monge-Elkan measure should be computed.
- Returns
The Monge-Elkan measure if both the lists/set are not None and do not have any missing tokens (i.e NaN), else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.monge_elkan(['Niall'], ['Neal']) 0.8049999999999999 >>> em.monge_elkan(['Niall'], None) nan
-
py_entitymatching.exact_match(d1, d2)¶ This function check if two objects are match exactly. Typically the objects are string, boolean and ints.
- Parameters
d1,d2 (str, boolean, int) – The input objects which should checked whether they match exactly.
- Returns
A value of 1 is returned if they match exactly, else returns 0. Further if one of the objects is NaN or None, it returns NaN.
Examples
>>> import py_entitymatching as em >>> em.exact_match('Niall', 'Neal') 0 >>> em.exact_match('Niall', 'Niall') 1 >>> em.exact_match(10, 10) 1 >>> em.exact_match(10, 20) 0 >>> em.exact_match(True, True) 1 >>> em.exact_match(False, True) 0 >>> em.exact_match(10, None) nan
-
py_entitymatching.rel_diff(d1, d2)¶ This function computes the relative difference between two numbers
- Parameters
d1,d2 (float) – The input numbers for which the relative difference must be computed.
- Returns
A float value of relative difference between the input numbers (if they are valid). Further if one of the input objects is NaN or None, it returns NaN.
Examples
>>> import py_entitymatching as em >>> em.rel_diff(100, 200) 0.6666666666666666 >>> em.rel_diff(100, 100) 0.0 >>> em.rel_diff(100, None) nan
-
py_entitymatching.abs_norm(d1, d2)¶ This function computes the absolute norm similarity between two numbers
- Parameters
d1,d2 (float) – Input numbers for which the absolute norm must be computed.
- Returns
A float value of absolute norm between the input numbers (if they are valid). Further if one of the input objects is NaN or None, it returns NaN.
Examples
>>> import py_entitymatching as em >>> em.abs_norm(100, 200) 0.5 >>> em.abs_norm(100, 100) 1.0 >>> em.abs_norm(100, None) nan
Supported Tokenizers¶
-
py_entitymatching.tok_qgram(input_string, q)¶ This function splits the input string into a list of q-grams. Note that, by default the input strings are padded and then tokenized.
- Parameters
input_string (string) – Input string that should be tokenized.
q (int) – q-val that should be used to tokenize the input string.
- Returns
A list of tokens, if the input string is not NaN, else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.tok_qgram('database', q=2) ['#d', 'da', 'at', 'ta', 'ab', 'ba', 'as', 'se', 'e$'] >>> em.tok_qgram('database', q=3) ['##d', '#da', 'dat', 'ata', 'tab', 'aba', 'bas', 'ase', 'se$', 'e$$'] >>> em.tok_qgram(None, q=2) nan
-
py_entitymatching.tok_delim(input_string, d)¶ This function splits the input string into a list of tokens (based on the delimiter).
- Parameters
input_string (string) – Input string that should be tokenized.
d (string) – Delimiter string.
- Returns
A list of tokens, if the input string is not NaN , else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.tok_delim('data science', ' ') ['data', 'science'] >>> em.tok_delim('data$#$science', '$#$') ['data', 'science'] >>> em.tok_delim(None, ' ') nan
-
py_entitymatching.tok_wspace(input_string)¶ This function splits the input string into a list of tokens (based on the white space).
- Parameters
input_string (string) – Input string that should be tokenized.
- Returns
A list of tokens, if the input string is not NaN , else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.tok_wspace('data science') ['data', 'science'] >>> em.tok_wspace('data science') ['data', 'science'] >>> em.tok_wspace(None) nan
-
py_entitymatching.tok_alphabetic(input_string)¶ This function returns a list of tokens that are maximal sequences of consecutive alphabetical characters.
- Parameters
input_string (string) – Input string that should be tokenized.
- Returns
A list of tokens, if the input string is not NaN , else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.tok_alphabetic('data99science, data#integration.') ['data', 'science', 'data', 'integration'] >>> em.tok_alphabetic('99') [] >>> em.tok_alphabetic(None) nan
-
py_entitymatching.tok_alphanumeric(input_string)¶ This function returns a list of tokens that are maximal sequences of consecutive alphanumeric characters.
- Parameters
input_string (string) – Input string that should be tokenized.
- Returns
A list of tokens, if the input string is not NaN , else returns NaN.
Examples
>>> import py_entitymatching as em >>> em.tok_alphanumeric('data9,(science), data9#.(integration).88') ['data9', 'science', 'data9', 'integration', '88'] >>> em.tok_alphanumeric('#.$') [] >>> em.tok_alphanumeric(None) nan
Matching¶
Splitting Data into Train and Test¶
-
py_entitymatching.split_train_test(labeled_data, train_proportion=0.5, random_state=None, verbose=True)¶ This function splits the input data into train and test.
Specifically, this function is just a wrapper of scikit-learn’s train_test_split function.
This function also takes care of copying the metadata from the input table to train and test splits.
- Parameters
labeled_data (DataFrame) – The input pandas DataFrame that needs to be split into train and test.
train_proportion (float) – A number between 0 and 1, indicating the proportion of tuples that should be included in the train split ( defaults to 0.5).
random_state (object) – A number of random number object (as in scikit-learn).
verbose (boolean) – A flag to indicate whether the debug information should be displayed.
- Returns
A Python dictionary containing two keys - train and test.
The value for the key ‘train’ is a pandas DataFrame containing tuples allocated from the input table based on train_proportion.
Similarly, the value for the key ‘test’ is a pandas DataFrame containing tuples for evaluation.
This function sets the output DataFrames (train, test) properties same as the input DataFrame.
Examples
>>> import py_entitymatching as em >>> # G is the labeled data or the feature vectors that should be split >>> train_test = em.split_train_test(G, train_proportion=0.5) >>> train, test = train_test['train'], train_test['test']
Supported Matchers¶
ML Matchers¶
-
class
py_entitymatching.DTMatcher(*args, **kwargs)¶ Decision Tree matcher.
- Parameters
*args,**kwargs – The arguments to scikit-learn’s Decision Tree classifier.
name (string) – The name of this matcher (defaults to None). If the matcher name is None, the class automatically generates a string and assigns it as the name.
Notes
For more details please see
-
fit(x=None, y=None, table=None, exclude_attrs=None, target_attr=None)¶ Fit interface for the matcher.
Specifically, there are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute.
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input feature vectors given as pandas DataFrame (defaults to None).
y (DatFrame) – The input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table.
-
predict(x=None, table=None, exclude_attrs=None, target_attr=None, append=False, return_probs=False, probs_attr=None, inplace=True)¶ Predict interface for the matcher.
Specifically, there are two ways the user can call the predict method. First, interface similar to scikit-learn where the feature vectors given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) .
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input pandas DataFrame containing only feature vectors (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors, and may be other attributes (defaults to None).
exclude_attrs (list) – A list of attributes to be excluded from the input table to get the feature vectors (defaults to None).
target_attr (string) – The attribute name where the predictions need to be stored in the input table (defaults to None).
probs_attr (string) – The attribute name where the prediction probabilities need to be stored in the input table (defaults to None).
append (boolean) – A flag to indicate whether the predictions need to be appended in the input DataFrame (defaults to False).
return_probs (boolean) – A flag to indicate where the prediction probabilities need to be returned (defaults to False). If set to True, returns the probability if the pair was a match.
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
- Returns
An array of predictions or a DataFrame with predictions updated.
-
class
py_entitymatching.RFMatcher(*args, **kwargs)¶ Random Forest matcher.
- Parameters
*args,**kwargs – The arguments to scikit-learn’s Random Forest classifier.
name (string) – The name of this matcher (defaults to None). If the matcher name is None, the class automatically generates a string and assigns it as the name.
-
fit(x=None, y=None, table=None, exclude_attrs=None, target_attr=None)¶ Fit interface for the matcher.
Specifically, there are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute.
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input feature vectors given as pandas DataFrame (defaults to None).
y (DatFrame) – The input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table.
-
predict(x=None, table=None, exclude_attrs=None, target_attr=None, append=False, return_probs=False, probs_attr=None, inplace=True)¶ Predict interface for the matcher.
Specifically, there are two ways the user can call the predict method. First, interface similar to scikit-learn where the feature vectors given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) .
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input pandas DataFrame containing only feature vectors (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors, and may be other attributes (defaults to None).
exclude_attrs (list) – A list of attributes to be excluded from the input table to get the feature vectors (defaults to None).
target_attr (string) – The attribute name where the predictions need to be stored in the input table (defaults to None).
probs_attr (string) – The attribute name where the prediction probabilities need to be stored in the input table (defaults to None).
append (boolean) – A flag to indicate whether the predictions need to be appended in the input DataFrame (defaults to False).
return_probs (boolean) – A flag to indicate where the prediction probabilities need to be returned (defaults to False). If set to True, returns the probability if the pair was a match.
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
- Returns
An array of predictions or a DataFrame with predictions updated.
-
class
py_entitymatching.SVMMatcher(*args, **kwargs)¶ SVM matcher.
- Parameters
*args,**kwargs – The arguments to scikit-learn’s SVM classifier.
name (string) – The name of this matcher (defaults to None). If the matcher name is None, the class automatically generates a string and assigns it as the name.
-
fit(x=None, y=None, table=None, exclude_attrs=None, target_attr=None)¶ Fit interface for the matcher.
Specifically, there are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute.
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input feature vectors given as pandas DataFrame (defaults to None).
y (DatFrame) – The input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table.
-
predict(x=None, table=None, exclude_attrs=None, target_attr=None, append=False, return_probs=False, probs_attr=None, inplace=True)¶ Predict interface for the matcher.
Specifically, there are two ways the user can call the predict method. First, interface similar to scikit-learn where the feature vectors given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) .
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input pandas DataFrame containing only feature vectors (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors, and may be other attributes (defaults to None).
exclude_attrs (list) – A list of attributes to be excluded from the input table to get the feature vectors (defaults to None).
target_attr (string) – The attribute name where the predictions need to be stored in the input table (defaults to None).
probs_attr (string) – The attribute name where the prediction probabilities need to be stored in the input table (defaults to None).
append (boolean) – A flag to indicate whether the predictions need to be appended in the input DataFrame (defaults to False).
return_probs (boolean) – A flag to indicate where the prediction probabilities need to be returned (defaults to False). If set to True, returns the probability if the pair was a match.
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
- Returns
An array of predictions or a DataFrame with predictions updated.
-
class
py_entitymatching.NBMatcher(*args, **kwargs)¶ Naive Bayes matcher.
- Parameters
*args,**kwargs – The arguments to scikit-learn’s Naive Bayes classifier.
name (string) – The name of this matcher (defaults to None). If the matcher name is None, the class automatically generates a string and assigns it as the name.
-
fit(x=None, y=None, table=None, exclude_attrs=None, target_attr=None)¶ Fit interface for the matcher.
Specifically, there are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute.
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input feature vectors given as pandas DataFrame (defaults to None).
y (DatFrame) – The input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table.
-
predict(x=None, table=None, exclude_attrs=None, target_attr=None, append=False, return_probs=False, probs_attr=None, inplace=True)¶ Predict interface for the matcher.
Specifically, there are two ways the user can call the predict method. First, interface similar to scikit-learn where the feature vectors given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) .
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input pandas DataFrame containing only feature vectors (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors, and may be other attributes (defaults to None).
exclude_attrs (list) – A list of attributes to be excluded from the input table to get the feature vectors (defaults to None).
target_attr (string) – The attribute name where the predictions need to be stored in the input table (defaults to None).
probs_attr (string) – The attribute name where the prediction probabilities need to be stored in the input table (defaults to None).
append (boolean) – A flag to indicate whether the predictions need to be appended in the input DataFrame (defaults to False).
return_probs (boolean) – A flag to indicate where the prediction probabilities need to be returned (defaults to False). If set to True, returns the probability if the pair was a match.
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
- Returns
An array of predictions or a DataFrame with predictions updated.
-
class
py_entitymatching.LinRegMatcher(*args, **kwargs)¶ Linear regression matcher.
- Parameters
*args,**kwargs – Arguments to scikit-learn’s Linear Regression matcher.
name (string) – Name that should be given to this matcher.
-
fit(x=None, y=None, table=None, exclude_attrs=None, target_attr=None)¶ Fit interface for the matcher.
Specifically, there are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute.
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input feature vectors given as pandas DataFrame (defaults to None).
y (DatFrame) – The input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table.
-
predict(x=None, table=None, exclude_attrs=None, target_attr=None, append=False, return_probs=False, probs_attr=None, inplace=True)¶ Predict interface for the matcher.
Specifically, there are two ways the user can call the predict method. First, interface similar to scikit-learn where the feature vectors given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) .
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input pandas DataFrame containing only feature vectors (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors, and may be other attributes (defaults to None).
exclude_attrs (list) – A list of attributes to be excluded from the input table to get the feature vectors (defaults to None).
target_attr (string) – The attribute name where the predictions need to be stored in the input table (defaults to None).
probs_attr (string) – The attribute name where the prediction probabilities need to be stored in the input table (defaults to None).
append (boolean) – A flag to indicate whether the predictions need to be appended in the input DataFrame (defaults to False).
return_probs (boolean) – A flag to indicate where the prediction probabilities need to be returned (defaults to False). If set to True, returns the probability if the pair was a match.
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
- Returns
An array of predictions or a DataFrame with predictions updated.
-
class
py_entitymatching.LogRegMatcher(*args, **kwargs)¶ Logistic Regression matcher.
- Parameters
*args,**kwargs – THe Arguments to scikit-learn’s Logistic Regression classifier.
name (string) – The name of this matcher (defaults to None). If the matcher name is None, the class automatically generates a string and assigns it as the name.
-
fit(x=None, y=None, table=None, exclude_attrs=None, target_attr=None)¶ Fit interface for the matcher.
Specifically, there are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute.
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input feature vectors given as pandas DataFrame (defaults to None).
y (DatFrame) – The input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table.
-
predict(x=None, table=None, exclude_attrs=None, target_attr=None, append=False, return_probs=False, probs_attr=None, inplace=True)¶ Predict interface for the matcher.
Specifically, there are two ways the user can call the predict method. First, interface similar to scikit-learn where the feature vectors given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) .
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input pandas DataFrame containing only feature vectors (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors, and may be other attributes (defaults to None).
exclude_attrs (list) – A list of attributes to be excluded from the input table to get the feature vectors (defaults to None).
target_attr (string) – The attribute name where the predictions need to be stored in the input table (defaults to None).
probs_attr (string) – The attribute name where the prediction probabilities need to be stored in the input table (defaults to None).
append (boolean) – A flag to indicate whether the predictions need to be appended in the input DataFrame (defaults to False).
return_probs (boolean) – A flag to indicate where the prediction probabilities need to be returned (defaults to False). If set to True, returns the probability if the pair was a match.
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
- Returns
An array of predictions or a DataFrame with predictions updated.
-
class
py_entitymatching.XGBoostMatcher(*args, **kwargs)¶ XGBoost matcher.
- Parameters
*args,**kwargs – The arguments to XGBoost classifier.
name (string) – The name of this matcher (defaults to None). If the matcher name is None, the class automatically generates a string and assigns it as the name.
-
fit(x=None, y=None, table=None, exclude_attrs=None, target_attr=None)¶ Fit interface for the matcher.
Specifically, there are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute.
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input feature vectors given as pandas DataFrame (defaults to None).
y (DatFrame) – The input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table.
-
predict(x=None, table=None, exclude_attrs=None, target_attr=None, append=False, return_probs=False, probs_attr=None, inplace=True)¶ Predict interface for the matcher.
Specifically, there are two ways the user can call the predict method. First, interface similar to scikit-learn where the feature vectors given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) .
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input pandas DataFrame containing only feature vectors (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors, and may be other attributes (defaults to None).
exclude_attrs (list) – A list of attributes to be excluded from the input table to get the feature vectors (defaults to None).
target_attr (string) – The attribute name where the predictions need to be stored in the input table (defaults to None).
probs_attr (string) – The attribute name where the prediction probabilities need to be stored in the input table (defaults to None).
append (boolean) – A flag to indicate whether the predictions need to be appended in the input DataFrame (defaults to False).
return_probs (boolean) – A flag to indicate where the prediction probabilities need to be returned (defaults to False). If set to True, returns the probability if the pair was a match.
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
- Returns
An array of predictions or a DataFrame with predictions updated.
Rule-Based Matcher¶
Selecting Matcher¶
-
py_entitymatching.select_matcher(matchers, x=None, y=None, table=None, exclude_attrs=None, target_attr=None, metric_to_select_matcher='precision', metrics_to_display=['precision', 'recall', 'f1'], k=5, n_jobs=-1, random_state=None)¶ This function selects a matcher from a given list of matchers based on a given metric.
Specifically, this function internally uses scikit-learn’s cross validation function to select a matcher. There are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
matchers (MLMatcher) – List of ML matchers to be selected from.
x (DataFrame) – Input feature vectors given as pandas DataFrame ( defaults to None).
y (DatFrame) – Input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – Input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table (defaults to None).
metric_to_select_matcher (string) – The metric based on which the matchers must be selected. The string can be one of ‘precision’, ‘recall’, ‘f1’ (defaults to ‘precision’).
metrics_to_display (list) – The metrics that will be displayed to the user. It should be a list of any of the strings ‘precision’, ‘recall’, or ‘f1’ (defaults to [‘precision’, ‘recall’, ‘f1’]).
k (int) – The k value for cross-validation (defaults to 5).
n_jobs (integer) – The number of CPUs to use to do the computation. -1 means ‘all CPUs (defaults to -1)’.
random_state (object) – Pseudo random number generator that should be used for splitting the data into folds (defaults to None).
- Returns
A dictionary containing three keys - selected matcher, cv_stats, and drill_down_cv_stats.
The selected matcher has a value that is a matcher (MLMatcher) object, cv_stats is a Dataframe containing average metrics for each matcher, and drill_down_cv_stats is a dictionary containing a table for each metric the user wants to display containing the score of the matchers for each fold.
- Raises:
- AssertionError: If metric_to_select_matcher is not one of ‘precision’, ‘recall’,
or ‘f1’.
- AssertionError: If each item in the list metrics_to_display is not one of
’precision’, ‘recall’, or ‘f1’.
Examples
>>> dt = em.DTMatcher() >>> rf = em.RFMatcher() # train is the feature vector containing user labels >>> result = em.select_matcher(matchers=[dt, rf], table=train, exclude_attrs=['_id', 'ltable_id', 'rtable_id'], target_attr='gold_labels', k=5)
Debugging Matcher¶
-
py_entitymatching.vis_debug_dt(matcher, train, test, exclude_attrs, target_attr)¶ Visual debugger for Decision Tree matcher.
- Parameters
matcher (DTMatcher) – The Decision tree matcher that should be debugged.
train (DataFrame) – The pandas DataFrame that will be used to train the matcher.
test (DataFrame) – The pandas DataFrame that will be used to test the matcher.
exclude_attrs (list) – The list of attributes to be excluded from train and test, for training and testing.
target_attr (string) – The attribute name in the ‘train’ containing the true labels.
Examples
>>> import py_entitymatching as em >>> dt = em.DTMatcher() # 'devel' is the labeled set used for development (e.g., selecting the best matcher) purposes >>> train_test = em.split_train_test(devel, 0.5) >>> train, test = train_test['train'], train_test['test'] >>> em.vis_debug_dt(dt, train, test, exclude_attrs=['_id', 'ltable_id', 'rtable_id'], target_attr='gold_labels')
-
py_entitymatching.vis_debug_rf(matcher, train, test, exclude_attrs, target_attr)¶ Visual debugger for Random Forest matcher.
- Parameters
matcher (RFMatcher) – The Random Forest matcher that should be debugged.
train (DataFrame) – The pandas DataFrame that will be used to train the matcher.
test (DataFrame) – The pandas DataFrame that will be used to test the matcher.
exclude_attrs (list) – The list of attributes to be excluded from train and test, for training and testing.
target_attr (string) – The attribute name in the ‘train’ containing the true labels.
Examples
>>> import py_entitymatching as em >>> rf = em.RFMatcher() # 'devel' is the labeled set used for development (e.g., selecting the best matcher) purposes >>> train_test = em.split_train_test(devel, 0.5) >>> train, test = train_test['train'], train_test['test'] >>> em.vis_debug_rf(rf, train, test, exclude_attrs=['_id', 'ltable_id', 'rtable_id'], target_attr='gold_labels')
-
py_entitymatching.debug_decisiontree_matcher(decision_tree, tuple_1, tuple_2, feature_table, table_columns, exclude_attrs=None)¶ This function is used to debug a decision tree matcher using two input tuples.
Specifically, this function takes in two tuples, gets the feature vector using the feature table and finally passes it to the decision tree and displays the path that the feature vector takes in the decision tree.
- Parameters
decision_tree (DTMatcher) – The input decision tree object that should be debugged.
tuple_1,tuple_2 (Series) – Input tuples that should be debugged.
feature_table (DataFrame) – Feature table containing the functions for the features.
table_columns (list) – List of all columns that will be outputted after generation of feature vectors.
exclude_attrs (list) – List of attributes that should be removed from the table columns.
- Raises
AssertionError – If the input feature table is not of type pandas DataFrame.
Examples
>>> import py_entitymatching as em >>> # devel is the labeled data used for development purposes, match_f is the feature table >>> H = em.extract_feat_vecs(devel, feat_table=match_f, attrs_after='gold_labels') >>> dt = em.DTMatcher() >>> dt.fit(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels') >>> # F is the feature vector got from evaluation set of the labeled data. >>> out = dt.predict(table=F, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels') >>> # A and B are input tables >>> em.debug_decisiontree_matcher(dt, A.ix[1], B.ix[2], match_f, H.columns, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels')
-
py_entitymatching.debug_randomforest_matcher(random_forest, tuple_1, tuple_2, feature_table, table_columns, exclude_attrs=None)¶ This function is used to debug a random forest matcher using two input tuples.
Specifically, this function takes in two tuples, gets the feature vector using the feature table and finally passes it to the random forest and displays the path that the feature vector takes in each of the decision trees that make up the random forest matcher.
- Parameters
random_forest (RFMatcher) – The input random forest object that should be debugged.
tuple_1,tuple_2 (Series) – Input tuples that should be debugged.
feature_table (DataFrame) – Feature table containing the functions for the features.
table_columns (list) – List of all columns that will be outputted after generation of feature vectors.
exclude_attrs (list) – List of attributes that should be removed from the table columns.
- Raises
AssertionError – If the input feature table is not of type pandas DataFrame.
Examples
>>> import py_entitymatching as em >>> # devel is the labeled data used for development purposes, match_f is the feature table >>> H = em.extract_feat_vecs(devel, feat_table=match_f, attrs_after='gold_labels') >>> rf = em.RFMatcher() >>> rf.fit(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels') >>> # F is the feature vector got from evaluation set of the labeled data. >>> out = rf.predict(table=F, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels') >>> # A and B are input tables >>> em.debug_randomforest_matcher(rf, A.ix[1], B.ix[2], match_f, H.columns, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels')
Triggers¶
-
class
py_entitymatching.MatchTrigger¶ -
add_action(value)¶ Adds an action to the match trigger. If the result of a rule is the same value as the condition status, then the action will be carried out. The condition status can be added with the function add_cond_status.
- Args:
value (integer): The action. Currently only the values 0 and 1 are supported.
- Examples:
>>> import py_entitymatching as em >>> mt = em.MatchTrigger() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> match_f = em.get_features_for_matching(A, B) >>> rule = ['title_title_lev_sim(ltuple, rtuple) > 0.7'] >>> mt.add_cond_rule(rule, match_f) >>> mt.add_cond_status(True) >>> mt.add_action(1)
-
add_cond_rule(conjunct_list, feature_table, rule_name=None)¶ Adds a rule to the match trigger.
- Parameters
conjunct_list (list) – A list of conjuncts specifying the rule.
feature_table (DataFrame) – A DataFrame containing all the features that are being referenced by the rule (defaults to None). If the feature_table is not supplied here, then it must have been specified during the creation of the rule-based blocker or using set_feature_table function. Otherwise an AssertionError will be raised and the rule will not be added to the rule-based blocker.
rule_name (string) – A string specifying the name of the rule to be added (defaults to None). If the rule_name is not specified then a name will be automatically chosen. If there is already a rule with the specified rule_name, then an AssertionError will be raised and the rule will not be added to the rule-based blocker.
- Returns
The name of the rule added (string).
- Raises
AssertionError – If rule_name already exists.
AssertionError – If feature_table is not a valid value parameter.
Examples
>>> import py_entitymatching as em >>> mt = em.MatchTrigger() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> match_f = em.get_features_for_matching(A, B) >>> rule = ['title_title_lev_sim(ltuple, rtuple) > 0.7'] >>> mt.add_cond_rule(rule, match_f)
-
add_cond_status(status)¶ Adds a condition status to the match trigger. If the result of a rule is the same value as the condition status, then the action will be carried out. The action can be added with the function add_action.
- Args:
status (boolean): The condition status.
- Examples:
>>> import py_entitymatching as em >>> mt = em.MatchTrigger() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> match_f = em.get_features_for_matching(A, B) >>> rule = ['title_title_lev_sim(ltuple, rtuple) > 0.7'] >>> mt.add_cond_rule(rule, match_f) >>> mt.add_cond_status(True) >>> mt.add_action(1)
-
delete_rule(rule_name)¶ Deletes a rule from the match trigger.
- Parameters
rule_name (string) – Name of the rule to be deleted.
Examples
>>> import py_entitymatching as em >>> mt = em.MatchTrigger() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> match_f = em.get_features_for_matching(A, B) >>> rule = ['title_title_lev_sim(ltuple, rtuple) > 0.7'] >>> mt.add_cond_rule(rule, match_f) >>> mt.delete_rule('rule_1')
-
execute(input_table, label_column, inplace=True, verbose=False)¶ Executes the rules of the match trigger for a table of matcher results.
- Parameters
input_table (DataFrame) – The input table of type pandas DataFrame containing tuple pairs and labels from matching (defaults to None).
label_column (string) – The attribute name where the predictions are stored in the input table (defaults to None).
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
- Returns
A DataFrame with predictions updated.
Examples
>>> import py_entitymatching as em >>> mt = em.MatchTrigger() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> match_f = em.get_features_for_matching(A, B) >>> rule = ['title_title_lev_sim(ltuple, rtuple) > 0.7'] >>> mt.add_cond_rule(rule, match_f) >>> mt.add_cond_status(True) >>> mt.add_action(1) >>> # The table H is a table with prediction labels generated from matching >>> mt.execute(input_table=H, label_column='predicted_labels', inplace=False)
-
get_rule(rule_name)¶ Returns the function corresponding to a rule.
- Parameters
rule_name (string) – Name of the rule.
- Returns
A function object corresponding to the specified rule.
Examples
>>> import py_entitymatching as em >>> mt = em.MatchTrigger() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> match_f = em.get_features_for_matching(A, B) >>> rule = ['title_title_lev_sim(ltuple, rtuple) > 0.7'] >>> mt.add_cond_rule(rule, match_f) >>> mt.get_rule()
-
get_rule_names()¶ Returns the names of all the rules in the match trigger.
- Returns
A list of names of all the rules in the match trigger (list).
Examples
>>> import py_entitymatching as em >>> mt = em.MatchTrigger() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> match_f = em.get_features_for_matching(A, B) >>> rule = ['title_title_lev_sim(ltuple, rtuple) > 0.7'] >>> mt.add_cond_rule(rule, match_f) >>> mt.get_rule_names()
-
set_feature_table(feature_table)¶ Sets feature table for the match trigger.
- Parameters
feature_table (DataFrame) – A DataFrame containing features.
Examples
>>> import py_entitymatching as em >>> mt = em.MatchTrigger() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> match_f = em.get_features_for_matching(A, B) >>> mt.set_feature_table(match_f)
-
view_rule(rule_name)¶ Prints the source code of the function corresponding to a rule.
- Parameters
rule_name (string) – Name of the rule to be viewed.
Examples
>>> import py_entitymatching as em >>> mt = em.MatchTrigger() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> match_f = em.get_features_for_matching(A, B) >>> rule = ['title_title_lev_sim(ltuple, rtuple) > 0.7'] >>> mt.add_cond_rule(rule, match_f) >>> mt.view_rule('rule_1')
-
Evaluating the Matching Output¶
-
py_entitymatching.eval_matches(data_frame, gold_label_attr, predicted_label_attr)¶ Evaluates the matches from the matcher.
Specifically, given a DataFrame containing golden labels and predicted labels, this function would evaluate the matches and return the accuracy results such as precision, recall and F1.
- Parameters
data_frame (DataFrame) – The input pandas DataFrame containing “gold” labels and “predicted” labels.
gold_label_attr (string) – An attribute in the input DataFrame containing “gold” labels.
predicted_label_attr (string) – An attribute in the input DataFrame containing “predicted” labels.
- Returns
A Python dictionary containing the accuracy measures such as precision, recall, F1.
- Raises
AssertionError – If data_frame is not of type pandas DataFrame.
AssertionError – If gold_label_attr is not of type string.
AssertionError – If predicted_label_attr is not of type string.
AssertionError – If the gold_label_attr is not in the input dataFrame.
AssertionError – If the predicted_label_attr is not in the input dataFrame.
Examples
>>> import py_entitymatching as em >>> # G is the labeled data used for development purposes, match_f is the feature table >>> H = em.extract_feat_vecs(G, feat_table=match_f, attrs_after='gold_labels') >>> dt = em.DTMatcher() >>> dt.fit(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels') >>> pred_table = dt.predict(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], append=True, target_attr='predicted_labels') >>> eval_summary = em.eval_matches(pred_table, 'gold_labels', 'predicted_labels')
-
py_entitymatching.print_eval_summary(eval_summary)¶ Prints a summary of evaluation results.
- Parameters
eval_summary (dictionary) – Dictionary containing evaluation results, typically from ‘eval_matches’ function.
Examples
>>> import py_entitymatching as em >>> # G is the labeled data used for development purposes, match_f is the feature table >>> H = em.extract_feat_vecs(G, feat_table=match_f, attrs_after='gold_labels') >>> dt = em.DTMatcher() >>> dt.fit(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels') >>> pred_table = dt.predict(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], append=True, target_attr='predicted_labels') >>> eval_summary = em.eval_matches(pred_table, 'gold_labels', 'predicted_labels') >>> em.print_eval_summary(eval_summary)
-
py_entitymatching.get_false_positives_as_df(table, eval_summary, verbose=False)¶ Select only the false positives from the input table and return as a DataFrame based on the evaluation results.
- Parameters
table (DataFrame) – The input table (pandas DataFrame) that was used for evaluation.
eval_summary (dictionary) – A Python dictionary containing evaluation results, typically from ‘eval_matches’ command.
- Returns
A pandas DataFrame containing only the False positives from the input table.
Further, this function sets the output DataFrame’s properties same as input DataFrame.
Examples
>>> import py_entitymatching as em >>> # G is the labeled data used for development purposes, match_f is the feature table >>> H = em.extract_feat_vecs(G, feat_table=match_f, attrs_after='gold_labels') >>> dt = em.DTMatcher() >>> dt.fit(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels') >>> pred_table = dt.predict(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], append=True, target_attr='predicted_labels') >>> eval_summary = em.eval_matches(pred_table, 'gold_labels', 'predicted_labels') >>> false_pos_df = em.get_false_positives_as_df(H, eval_summary)
-
py_entitymatching.get_false_negatives_as_df(table, eval_summary, verbose=False)¶ Select only the false negatives from the input table and return as a DataFrame based on the evaluation results.
- Parameters
table (DataFrame) – The input table (pandas DataFrame) that was used for evaluation.
eval_summary (dictionary) – A Python dictionary containing evaluation results, typically from ‘eval_matches’ command.
- Returns
A pandas DataFrame containing only the false negatives from the input table.
Further, this function sets the output DataFrame’s properties same as input DataFrame.
Examples
>>> import py_entitymatching as em >>> # G is the labeled data used for development purposes, match_f is the feature table >>> H = em.extract_feat_vecs(G, feat_table=match_f, attrs_after='gold_labels') >>> dt = em.DTMatcher() >>> dt.fit(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], target_attr='gold_labels') >>> pred_table = dt.predict(table=H, exclude_attrs=['_id', 'ltable_id', 'rtable_id', 'gold_labels'], append=True, target_attr='predicted_labels') >>> eval_summary = em.eval_matches(pred_table, 'gold_labels', 'predicted_labels') >>> false_neg_df = em.get_false_negatives_as_df(H, eval_summary)
Experimental Commands¶
Commands Implemented Using Dask¶
Downsampling¶
-
py_entitymatching.dask.dask_down_sample.dask_down_sample(ltable, rtable, size, y_param, show_progress=True, verbose=False, seed=None, rem_stop_words=True, rem_puncs=True, n_ltable_chunks=1, n_sample_rtable_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
This command down samples two tables A and B into smaller tables A’ and B’ respectively. Specifically, first it randomly selects size tuples from the table B to be table B’. Next, it builds an inverted index I (token, tuple_id) on table A. For each tuple x ∈ B’, the algorithm finds a set P of k/2 tuples from I that match x, and a set Q of k/2 tuples randomly selected from A - P. The idea is for A’ and B’ to share some matches yet be as representative of A and B as possible.
- Parameters
ltable (DataFrame) – The left input table, i.e., table A.
rtable (DataFrame) – The right input table, i.e., table B.
size (int) – The size that table B should be down sampled to.
y_param (int) – The parameter to control the down sample size of table A. Specifically, the down sampled size of table A should be close to size * y_param.
show_progress (boolean) – A flag to indicate whether a progress bar should be displayed (defaults to True).
verbose (boolean) – A flag to indicate whether the debug information should be displayed (defaults to False).
seed (int) – The seed for the pseudo random number generator to select the tuples from A and B (defaults to None).
rem_stop_words (boolean) – A flag to indicate whether a default set of stop words must be removed.
rem_puncs (boolean) – A flag to indicate whether the punctuations must be removed from the strings.
n_ltable_chunks (int) – The number of partitions for ltable (defaults to 1). If it is set to -1, the number of partitions will be set to the number of cores in the machine.
n_sample_rtable_chunks (int) – The number of partitions for the sampled rtable (defaults to 1)
- Returns
Down sampled tables A and B as pandas DataFrames.
- Raises
AssertionError – If any of the input tables (table_a, table_b) are empty or not a DataFrame.
AssertionError – If size or y_param is empty or 0 or not a valid integer value.
AssertionError – If seed is not a valid integer value.
AssertionError – If verbose is not of type bool.
AssertionError – If show_progress is not of type bool.
AssertionError – If n_ltable_chunks is not of type int.
AssertionError – If n_sample_rtable_chunks is not of type int.
Examples
>>> from py_entitymatching.dask.dask_down_sample import dask_down_sample >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> sample_A, sample_B = dask_down_sample(A, B, 500, 1, n_ltable_chunks=-1, n_sample_rtable_chunks=-1) # Example with seed = 0. This means the same sample data set will be returned # each time this function is run. >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> sample_A, sample_B = dask_down_sample(A, B, 500, 1, seed=0, n_ltable_chunks=-1, n_sample_rtable_chunks=-1)
Blocking¶
-
class
py_entitymatching.dask.dask_attr_equiv_blocker.DaskAttrEquivalenceBlocker(*args, **kwargs)¶ WARNING THIS BLOCKER IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Blocks based on the equivalence of attribute values.
-
block_candset(candset, l_block_attr, r_block_attr, allow_missing=False, verbose=False, show_progress=True, n_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Blocks an input candidate set of tuple pairs based on attribute equivalence. Finds tuple pairs from an input candidate set of tuple pairs such that the value of attribute l_block_attr of the left tuple in a tuple pair exactly matches the value of attribute r_block_attr of the right tuple in the tuple pair.
- Parameters
candset (DataFrame) – The input candidate set of tuple pairs.
l_block_attr (string) – The blocking attribute in left table.
r_block_attr (string) – The blocking attribute in right table.
allow_missing (boolean) – A flag to indicate whether tuple pairs with missing value in at least one of the blocking attributes should be included in the output candidate set (defaults to False). If this flag is set to True, a tuple pair with missing value in either blocking attribute will be retained in the output candidate set.
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_chunks (int) – The number of partitions to split the candidate set. If it is set to -1, the number of partitions will be set to the number of cores in the machine.
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If candset is not of type pandas DataFrame.
AssertionError – If l_block_attr is not of type string.
AssertionError – If r_block_attr is not of type string.
AssertionError – If verbose is not of type boolean.
AssertionError – If n_chunks is not of type int.
AssertionError – If l_block_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
Examples
>>> import py_entitymatching as em >>> from py_entitymatching.dask.dask_attr_equiv_blocker import DaskAttrEquivalenceBlocker >>> ab = DaskAttrEquivalenceBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> C = ab.block_tables(A, B, 'zipcode', 'zipcode', l_output_attrs=['name'], r_output_attrs=['name']) >>> D1 = ab.block_candset(C, 'age', 'age', allow_missing=True) # Include all possible tuple pairs with missing values >>> D2 = ab.block_candset(C, 'age', 'age', allow_missing=True) # Execute blocking using multiple cores >>> D3 = ab.block_candset(C, 'age', 'age', n_chunks=-1)
-
block_tables(ltable, rtable, l_block_attr, r_block_attr, l_output_attrs=None, r_output_attrs=None, l_output_prefix='ltable_', r_output_prefix='rtable_', allow_missing=False, verbose=False, n_ltable_chunks=1, n_rtable_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK
Blocks two tables based on attribute equivalence. Conceptually, this will check l_block_attr=r_block_attr for each tuple pair from the Cartesian product of tables ltable and rtable. It outputs a Pandas dataframe object with tuple pairs that satisfy the equality condition. The dataframe will include attributes ‘_id’, key attribute from ltable, key attributes from rtable, followed by lists l_output_attrs and r_output_attrs if they are specified. Each of these output and key attributes will be prefixed with given l_output_prefix and r_output_prefix. If allow_missing is set to True then all tuple pairs with missing value in at least one of the tuples will be included in the output dataframe. Further, this will update the following metadata in the catalog for the output table: (1) key, (2) ltable, (3) rtable, (4) fk_ltable, and (5) fk_rtable.
- Parameters
ltable (DataFrame) – The left input table.
rtable (DataFrame) – The right input table.
l_block_attr (string) – The blocking attribute in left table.
r_block_attr (string) – The blocking attribute in right table.
l_output_attrs (list) – A list of attribute names from the left table to be included in the output candidate set (defaults to None).
r_output_attrs (list) – A list of attribute names from the right table to be included in the output candidate set (defaults to None).
l_output_prefix (string) – The prefix to be used for the attribute names coming from the left table in the output candidate set (defaults to ‘ltable_’).
r_output_prefix (string) – The prefix to be used for the attribute names coming from the right table in the output candidate set (defaults to ‘rtable_’).
allow_missing (boolean) – A flag to indicate whether tuple pairs with missing value in at least one of the blocking attributes should be included in the output candidate set (defaults to False). If this flag is set to True, a tuple in ltable with missing value in the blocking attribute will be matched with every tuple in rtable and vice versa.
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
n_ltable_chunks (int) – The number of partitions to split the left table ( defaults to 1). If it is set to -1, then the number of partitions is set to the number of cores in the machine.
n_rtable_chunks (int) – The number of partitions to split the right table ( defaults to 1). If it is set to -1, then the number of partitions is set to the number of cores in the machine.
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
AssertionError – If l_block_attr is not of type string.
AssertionError – If r_block_attr is not of type string.
AssertionError – If l_output_attrs is not of type of list.
AssertionError – If r_output_attrs is not of type of list.
AssertionError – If the values in l_output_attrs is not of type string.
AssertionError – If the values in r_output_attrs is not of type string.
AssertionError – If l_output_prefix is not of type string.
AssertionError – If r_output_prefix is not of type string.
AssertionError – If verbose is not of type boolean.
AssertionError – If allow_missing is not of type boolean.
AssertionError – If n_ltable_chunks is not of type int.
AssertionError – If n_rtable_chunks is not of type int.
AssertionError – If l_block_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
AssertionError – If l_out_attrs are not in the ltable.
AssertionError – If r_out_attrs are not in the rtable.
Examples
>>> import py_entitymatching as em >>> from py_entitymatching.dask.dask_attr_equiv_blocker import DaskAttrEquivalenceBlocker >>> ab = DaskAttrEquivalenceBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> C1 = ab.block_tables(A, B, 'zipcode', 'zipcode', l_output_attrs=['name'], r_output_attrs=['name']) # Include all possible tuple pairs with missing values >>> C2 = ab.block_tables(A, B, 'zipcode', 'zipcode', l_output_attrs=['name'], r_output_attrs=['name'], allow_missing=True)
-
block_tuples(ltuple, rtuple, l_block_attr, r_block_attr, allow_missing=False)¶ Blocks a tuple pair based on attribute equivalence.
- Parameters
ltuple (Series) – The input left tuple.
rtuple (Series) – The input right tuple.
l_block_attr (string) – The blocking attribute in left tuple.
r_block_attr (string) – The blocking attribute in right tuple.
allow_missing (boolean) – A flag to indicate whether a tuple pair with missing value in at least one of the blocking attributes should be blocked (defaults to False). If this flag is set to True, the pair will be kept if either ltuple has missing value in l_block_attr or rtuple has missing value in r_block_attr or both.
- Returns
A status indicating if the tuple pair is blocked, i.e., the values of l_block_attr in ltuple and r_block_attr in rtuple are different (boolean).
Examples
>>> import py_entitymatching as em >>> from py_entitymatching.dask.dask_attr_equiv_blocker import DaskAttrEquivalenceBlocker >>> ab = DaskAttrEquivalenceBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> status = ab.block_tuples(A.ix[0], B.ix[0], 'zipcode', 'zipcode')
-
-
class
py_entitymatching.dask.dask_overlap_blocker.DaskOverlapBlocker¶ -
block_candset(candset, l_overlap_attr, r_overlap_attr, rem_stop_words=False, q_val=None, word_level=True, overlap_size=1, allow_missing=False, verbose=False, show_progress=True, n_chunks=-1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Blocks an input candidate set of tuple pairs based on the overlap of token sets of attribute values. Finds tuple pairs from an input candidate set of tuple pairs such that the overlap between (a) the set of tokens obtained by tokenizing the value of attribute l_overlap_attr of the left tuple in a tuple pair, and (b) the set of tokens obtained by tokenizing the value of attribute r_overlap_attr of the right tuple in the tuple pair, is above a certain threshold.
- Parameters
candset (DataFrame) – The input candidate set of tuple pairs.
l_overlap_attr (string) – The overlap attribute in left table.
r_overlap_attr (string) – The overlap attribute in right table.
rem_stop_words (boolean) – A flag to indicate whether stop words (e.g., a, an, the) should be removed from the token sets of the overlap attribute values (defaults to False).
q_val (int) – The value of q to use if the overlap attributes values are to be tokenized as qgrams (defaults to None).
word_level (boolean) – A flag to indicate whether the overlap attributes should be tokenized as words (i.e, using whitespace as delimiter) (defaults to True).
overlap_size (int) – The minimum number of tokens that must overlap (defaults to 1).
allow_missing (boolean) – A flag to indicate whether tuple pairs with missing value in at least one of the blocking attributes should be included in the output candidate set (defaults to False). If this flag is set to True, a tuple pair with missing value in either blocking attribute will be retained in the output candidate set.
verbose (boolean) –
A flag to indicate whether the debug information
should be logged (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_chunks (int) – The number of partitions to split the candidate set. If it is set to -1, the number of partitions will be set to the number of cores in the machine.
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If candset is not of type pandas DataFrame.
AssertionError – If l_overlap_attr is not of type string.
AssertionError – If r_overlap_attr is not of type string.
AssertionError – If q_val is not of type int.
AssertionError – If word_level is not of type boolean.
AssertionError – If overlap_size is not of type int.
AssertionError – If verbose is not of type boolean.
AssertionError – If allow_missing is not of type boolean.
AssertionError – If show_progress is not of type boolean.
AssertionError – If n_chunks is not of type int.
AssertionError – If l_overlap_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
SyntaxError – If q_val is set to a valid value and word_level is set to True.
SyntaxError – If q_val is set to None and word_level is set to False.
Examples
>>> import py_entitymatching as em >>> from py_entitymatching.dask.dask_overlap_blocker import DaskOverlapBlocker >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> ob = DaskOverlapBlocker() >>> C = ob.block_tables(A, B, 'address', 'address', l_output_attrs=['name'], r_output_attrs=['name'])
>>> D1 = ob.block_candset(C, 'name', 'name', allow_missing=True) # Include all possible tuple pairs with missing values >>> D2 = ob.block_candset(C, 'name', 'name', allow_missing=True) # Execute blocking using multiple cores >>> D3 = ob.block_candset(C, 'name', 'name', n_chunks=-1) # Use q-gram tokenizer >>> D2 = ob.block_candset(C, 'name', 'name', word_level=False, q_val=2)
-
block_tables(ltable, rtable, l_overlap_attr, r_overlap_attr, rem_stop_words=False, q_val=None, word_level=True, overlap_size=1, l_output_attrs=None, r_output_attrs=None, l_output_prefix='ltable_', r_output_prefix='rtable_', allow_missing=False, verbose=False, show_progress=True, n_ltable_chunks=1, n_rtable_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Blocks two tables based on the overlap of token sets of attribute values. Finds tuple pairs from left and right tables such that the overlap between (a) the set of tokens obtained by tokenizing the value of attribute l_overlap_attr of a tuple from the left table, and (b) the set of tokens obtained by tokenizing the value of attribute r_overlap_attr of a tuple from the right table, is above a certain threshold.
- Parameters
ltable (DataFrame) – The left input table.
rtable (DataFrame) – The right input table.
l_overlap_attr (string) – The overlap attribute in left table.
r_overlap_attr (string) – The overlap attribute in right table.
rem_stop_words (boolean) – A flag to indicate whether stop words (e.g., a, an, the) should be removed from the token sets of the overlap attribute values (defaults to False).
q_val (int) – The value of q to use if the overlap attributes values are to be tokenized as qgrams (defaults to None).
word_level (boolean) – A flag to indicate whether the overlap attributes should be tokenized as words (i.e, using whitespace as delimiter) (defaults to True).
overlap_size (int) – The minimum number of tokens that must overlap (defaults to 1).
l_output_attrs (list) – A list of attribute names from the left table to be included in the output candidate set (defaults to None).
r_output_attrs (list) – A list of attribute names from the right table to be included in the output candidate set (defaults to None).
l_output_prefix (string) – The prefix to be used for the attribute names coming from the left table in the output candidate set (defaults to ‘ltable_’).
r_output_prefix (string) – The prefix to be used for the attribute names coming from the right table in the output candidate set (defaults to ‘rtable_’).
allow_missing (boolean) – A flag to indicate whether tuple pairs with missing value in at least one of the blocking attributes should be included in the output candidate set (defaults to False). If this flag is set to True, a tuple in ltable with missing value in the blocking attribute will be matched with every tuple in rtable and vice versa.
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_ltable_chunks (int) – The number of partitions to split the left table ( defaults to 1). If it is set to -1, then the number of partitions is set to the number of cores in the machine.
n_rtable_chunks (int) – The number of partitions to split the right table ( defaults to 1). If it is set to -1, then the number of partitions is set to the number of cores in the machine.
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
AssertionError – If l_overlap_attr is not of type string.
AssertionError – If r_overlap_attr is not of type string.
AssertionError – If l_output_attrs is not of type of list.
AssertionError – If r_output_attrs is not of type of list.
AssertionError – If the values in l_output_attrs is not of type string.
AssertionError – If the values in r_output_attrs is not of type string.
AssertionError – If l_output_prefix is not of type string.
AssertionError – If r_output_prefix is not of type string.
AssertionError – If q_val is not of type int.
AssertionError – If word_level is not of type boolean.
AssertionError – If overlap_size is not of type int.
AssertionError – If verbose is not of type boolean.
AssertionError – If allow_missing is not of type boolean.
AssertionError – If show_progress is not of type boolean.
AssertionError – If n_ltable_chunks is not of type int.
AssertionError – If n_rtable_chunks is not of type int.
AssertionError – If l_overlap_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
AssertionError – If l_output_attrs are not in the ltable.
AssertionError – If r_output_attrs are not in the rtable.
SyntaxError – If q_val is set to a valid value and word_level is set to True.
SyntaxError – If q_val is set to None and word_level is set to False.
Examples
>>> from py_entitymatching.dask.dask_overlap_blocker import DaskOverlapBlocker >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> ob = DaskOverlapBlocker() # Use all cores # # Use word-level tokenizer >>> C1 = ob.block_tables(A, B, 'address', 'address', l_output_attrs=['name'], r_output_attrs=['name'], word_level=True, overlap_size=1, n_ltable_chunks=-1, n_rtable_chunks=-1) # # Use q-gram tokenizer >>> C2 = ob.block_tables(A, B, 'address', 'address', l_output_attrs=['name'], r_output_attrs=['name'], word_level=False, q_val=2, n_ltable_chunks=-1, n_rtable_chunks=-1) # # Include all possible missing values >>> C3 = ob.block_tables(A, B, 'address', 'address', l_output_attrs=['name'], r_output_attrs=['name'], allow_missing=True, n_ltable_chunks=-1, n_rtable_chunks=-1)
-
block_tuples(ltuple, rtuple, l_overlap_attr, r_overlap_attr, rem_stop_words=False, q_val=None, word_level=True, overlap_size=1, allow_missing=False)¶ Blocks a tuple pair based on the overlap of token sets of attribute values.
- Parameters
ltuple (Series) – The input left tuple.
rtuple (Series) – The input right tuple.
l_overlap_attr (string) – The overlap attribute in left tuple.
r_overlap_attr (string) – The overlap attribute in right tuple.
rem_stop_words (boolean) – A flag to indicate whether stop words (e.g., a, an, the) should be removed from the token sets of the overlap attribute values (defaults to False).
q_val (int) – A value of q to use if the overlap attributes values are to be tokenized as qgrams (defaults to None).
word_level (boolean) – A flag to indicate whether the overlap attributes should be tokenized as words (i.e, using whitespace as delimiter) (defaults to True).
overlap_size (int) – The minimum number of tokens that must overlap (defaults to 1).
allow_missing (boolean) – A flag to indicate whether a tuple pair with missing value in at least one of the blocking attributes should be blocked (defaults to False). If this flag is set to True, the pair will be kept if either ltuple has missing value in l_block_attr or rtuple has missing value in r_block_attr or both.
- Returns
A status indicating if the tuple pair is blocked (boolean).
Examples
>>> import py_entitymatching as em >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> ob = em.OverlapBlocker() >>> status = ob.block_tuples(A.ix[0], B.ix[0], 'address', 'address')
-
-
class
py_entitymatching.dask.dask_rule_based_blocker.DaskRuleBasedBlocker(*args, **kwargs)¶ WARNING THIS BLOCKER IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Blocks based on a sequence of blocking rules supplied by the user.
-
add_rule(conjunct_list, feature_table=None, rule_name=None)¶ Adds a rule to the rule-based blocker.
- Parameters
conjunct_list (list) – A list of conjuncts specifying the rule.
feature_table (DataFrame) – A DataFrame containing all the features that are being referenced by the rule (defaults to None). If the feature_table is not supplied here, then it must have been specified during the creation of the rule-based blocker or using set_feature_table function. Otherwise an AssertionError will be raised and the rule will not be added to the rule-based blocker.
rule_name (string) – A string specifying the name of the rule to be added (defaults to None). If the rule_name is not specified then a name will be automatically chosen. If there is already a rule with the specified rule_name, then an AssertionError will be raised and the rule will not be added to the rule-based blocker.
- Returns
The name of the rule added (string).
- Raises
AssertionError – If rule_name already exists.
AssertionError – If feature_table is not a valid value parameter.
Examples
>>> import py_entitymatching >>> from py_entitymatching.dask.dask_rule_based_blocker import DaskRuleBasedBlocker >>> rb = DaskRuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, rule_name='rule1')
-
block_candset(candset, verbose=False, show_progress=True, n_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK
Blocks an input candidate set of tuple pairs based on a sequence of blocking rules supplied by the user. Finds tuple pairs from an input candidate set of tuple pairs that survive the sequence of blocking rules. A tuple pair survives the sequence of blocking rules if none of the rules in the sequence returns True for that pair. If any of the rules returns True, then the pair is blocked (dropped).
- Parameters
candset (DataFrame) – The input candidate set of tuple pairs.
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_chunks (int) – The number of partitions to split the candidate set. If it is set to -1, the number of partitions will be set to the number of cores in the machine.
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If candset is not of type pandas DataFrame.
AssertionError – If verbose is not of type boolean.
AssertionError – If n_chunks is not of type int.
AssertionError – If show_progress is not of type boolean.
AssertionError – If l_block_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
AssertionError – If there are no rules to apply.
Examples
>>> import py_entitymatching as em >>> from py_entitymatching.dask.dask_rule_based_blocker import DaskRuleBasedBlocker >>> rb = DaskRuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, feature_table=block_f) >>> D = rb.block_tables(C) # C is the candidate set.
-
block_tables(ltable, rtable, l_output_attrs=None, r_output_attrs=None, l_output_prefix='ltable_', r_output_prefix='rtable_', verbose=False, show_progress=True, n_ltable_chunks=1, n_rtable_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK
Blocks two tables based on the sequence of rules supplied by the user. Finds tuple pairs from left and right tables that survive the sequence of blocking rules. A tuple pair survives the sequence of blocking rules if none of the rules in the sequence returns True for that pair. If any of the rules returns True, then the pair is blocked.
- Parameters
ltable (DataFrame) – The left input table.
rtable (DataFrame) – The right input table.
l_output_attrs (list) – A list of attribute names from the left table to be included in the output candidate set (defaults to None).
r_output_attrs (list) – A list of attribute names from the right table to be included in the output candidate set (defaults to None).
l_output_prefix (string) – The prefix to be used for the attribute names coming from the left table in the output candidate set (defaults to ‘ltable_’).
r_output_prefix (string) – The prefix to be used for the attribute names coming from the right table in the output candidate set (defaults to ‘rtable_’).
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_ltable_chunks (int) – The number of partitions to split the left table ( defaults to 1). If it is set to -1, then the number of partitions is set to the number of cores in the machine.
n_rtable_chunks (int) – The number of partitions to split the right table ( defaults to 1). If it is set to -1, then the number of partitions is set to the number of cores in the machine.
- Returns
A candidate set of tuple pairs that survived the sequence of blocking rules (DataFrame).
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
AssertionError – If l_output_attrs is not of type of list.
AssertionError – If r_output_attrs is not of type of list.
AssertionError – If the values in l_output_attrs is not of type string.
AssertionError – If the values in r_output_attrs is not of type string.
AssertionError – If the input l_output_prefix is not of type string.
AssertionError – If the input r_output_prefix is not of type string.
AssertionError – If verbose is not of type boolean.
AssertionError – If show_progress is not of type boolean.
AssertionError – If n_ltable_chunks is not of type int.
AssertionError – If n_rtable_chunks is not of type int.
AssertionError – If l_out_attrs are not in the ltable.
AssertionError – If r_out_attrs are not in the rtable.
AssertionError – If there are no rules to apply.
Examples
>>> import py_entitymatching as em >>> from py_entitymatching.dask.dask_rule_based_blocker import DaskRuleBasedBlocker >>> rb = DaskRuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, feature_table=block_f) >>> C = rb.block_tables(A, B)
-
block_tuples(ltuple, rtuple)¶ Blocks a tuple pair based on a sequence of blocking rules supplied by the user.
- Parameters
ltuple (Series) – The input left tuple.
rtuple (Series) – The input right tuple.
- Returns
A status indicating if the tuple pair is blocked by applying the sequence of blocking rules (boolean).
Examples
>>> import py_entitymatching as em >>> from py_entitymatching.dask.dask_rule_based_blocker import DaskRuleBasedBlocker >>> rb = DaskRuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, feature_table=block_f) >>> D = rb.block_tuples(A.ix[0], B.ix[1)
-
delete_rule(rule_name)¶ Deletes a rule from the rule-based blocker.
- Parameters
rule_name (string) – Name of the rule to be deleted.
Examples
>>> import py_entitymatching as em >>> from py_entitymatching.dask.dask_rule_based_blocker import DaskRuleBasedBlocker >>> rb = DaskRuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, block_f, rule_name='rule_1') >>> rb.delete_rule('rule_1')
-
get_rule(rule_name)¶ Returns the function corresponding to a rule.
- Parameters
rule_name (string) – Name of the rule.
- Returns
A function object corresponding to the specified rule.
Examples
>>> import py_entitymatching as em >>> rb = em.DaskRuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, feature_table=block_f, rule_name='rule_1') >>> rb.get_rule()
-
get_rule_names()¶ Returns the names of all the rules in the rule-based blocker.
- Returns
A list of names of all the rules in the rule-based blocker (list).
Examples
>>> import py_entitymatching as em >>> rb = em.DaskRuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, block_f, rule_name='rule_1') >>> rb.get_rule_names()
-
set_feature_table(feature_table)¶ Sets feature table for the rule-based blocker.
- Parameters
feature_table (DataFrame) – A DataFrame containing features.
Examples
>>> import py_entitymatching as em >>> rb = em.DaskRuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rb.set_feature_table(block_f)
-
view_rule(rule_name)¶ Prints the source code of the function corresponding to a rule.
- Parameters
rule_name (string) – Name of the rule to be viewed.
Examples
>>> import py_entitymatching as em >>> rb = em.DaskRuleBasedBlocker() >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='id') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='id') >>> block_f = em.get_features_for_blocking(A, B) >>> rule = ['name_name_lev(ltuple, rtuple) > 3'] >>> rb.add_rule(rule, block_f, rule_name='rule_1') >>> rb.view_rule('rule_1')
-
-
class
py_entitymatching.dask.dask_black_box_blocker.DaskBlackBoxBlocker(*args, **kwargs)¶ WARNING THIS BLOCKER IS EXPERIMENTAL AND NOT TESTED. USE A0T YOUR OWN RISK.
Blocks based on a black box function specified by the user.
-
block_candset(candset, verbose=True, show_progress=True, n_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Blocks an input candidate set of tuple pairs based on a black box blocking function specified by the user.
Finds tuple pairs from an input candidate set of tuple pairs that survive the black box function. A tuple pair survives the black box blocking function if the function returns False for that pair, otherwise the tuple pair is dropped.
- Parameters
candset (DataFrame) – The input candidate set of tuple pairs.
verbose (boolean) – A flag to indicate whether logging should be done (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_chunks (int) – The number of partitions to split the candidate set. If it is set to -1, the number of partitions will be set to the number of cores in the machine.
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If candset is not of type pandas DataFrame.
AssertionError – If verbose is not of type boolean.
AssertionError – If n_chunks is not of type int.
AssertionError – If show_progress is not of type boolean.
AssertionError – If l_block_attr is not in the ltable columns.
AssertionError – If r_block_attr is not in the rtable columns.
Examples
>>> def match_last_name(ltuple, rtuple): # assume that there is a 'name' attribute in the input tables # and each value in it has two words l_last_name = ltuple['name'].split()[1] r_last_name = rtuple['name'].split()[1] if l_last_name != r_last_name: return True else: return False >>> import py_entitymatching as em >>> from py_entitymatching.dask.dask_black_box_blocker import DaskBlackBoxBlocker >>> bb = DaskBlackBoxBlocker() >>> bb.set_black_box_function(match_last_name) >>> D = bb.block_candset(C) # C is an output from block_tables
-
block_tables(ltable, rtable, l_output_attrs=None, r_output_attrs=None, l_output_prefix='ltable_', r_output_prefix='rtable_', verbose=False, show_progress=True, n_ltable_chunks=1, n_rtable_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Blocks two tables based on a black box blocking function specified by the user. Finds tuple pairs from left and right tables that survive the black box function. A tuple pair survives the black box blocking function if the function returns False for that pair, otherwise the tuple pair is dropped.
- Parameters
ltable (DataFrame) – The left input table.
rtable (DataFrame) – The right input table.
l_output_attrs (list) – A list of attribute names from the left table to be included in the output candidate set (defaults to None).
r_output_attrs (list) – A list of attribute names from the right table to be included in the output candidate set (defaults to None).
l_output_prefix (string) – The prefix to be used for the attribute names coming from the left table in the output candidate set (defaults to ‘ltable_’).
r_output_prefix (string) – The prefix to be used for the attribute names coming from the right table in the output candidate set (defaults to ‘rtable_’).
verbose (boolean) – A flag to indicate whether the debug information should be logged (defaults to False).
show_progress (boolean) – A flag to indicate whether progress should be displayed to the user (defaults to True).
n_ltable_chunks (int) – The number of partitions to split the left table ( defaults to 1). If it is set to -1, then the number of partitions is set to the number of cores in the machine.
n_rtable_chunks (int) – The number of partitions to split the right table ( defaults to 1). If it is set to -1, then the number of partitions is set to the number of cores in the machine.
- Returns
A candidate set of tuple pairs that survived blocking (DataFrame).
- Raises
AssertionError – If ltable is not of type pandas DataFrame.
AssertionError – If rtable is not of type pandas DataFrame.
AssertionError – If l_output_attrs is not of type of list.
AssertionError – If r_output_attrs is not of type of list.
AssertionError – If values in l_output_attrs is not of type string.
AssertionError – If values in r_output_attrs is not of type string.
AssertionError – If l_output_prefix is not of type string.
AssertionError – If r_output_prefix is not of type string.
AssertionError – If verbose is not of type boolean.
AssertionError – If show_progress is not of type boolean.
AssertionError – If n_ltable_chunks is not of type int.
AssertionError – If n_rtable_chunks is not of type int.
AssertionError – If l_out_attrs are not in the ltable.
AssertionError – If r_out_attrs are not in the rtable.
Examples
>>> def match_last_name(ltuple, rtuple): # assume that there is a 'name' attribute in the input tables # and each value in it has two words l_last_name = ltuple['name'].split()[1] r_last_name = rtuple['name'].split()[1] if l_last_name != r_last_name: return True else: return False >>> import py_entitymatching as em >>> from py_entitymatching.dask.dask_black_box_blocker DaskBlackBoxBlocker >>> bb = DaskBlackBoxBlocker() >>> bb.set_black_box_function(match_last_name) >>> C = bb.block_tables(A, B, l_output_attrs=['name'], r_output_attrs=['name'] )
-
block_tuples(ltuple, rtuple)¶ Blocks a tuple pair based on a black box blocking function specified by the user.
Takes a tuple pair as input, applies the black box blocking function to it, and returns True (if the intention is to drop the pair) or False (if the intention is to keep the tuple pair).
- Parameters
ltuple (Series) – input left tuple.
rtuple (Series) – input right tuple.
- Returns
A status indicating if the tuple pair should be dropped or kept, based on the black box blocking function (boolean).
Examples
>>> def match_last_name(ltuple, rtuple): # assume that there is a 'name' attribute in the input tables # and each value in it has two words l_last_name = ltuple['name'].split()[1] r_last_name = rtuple['name'].split()[1] if l_last_name != r_last_name: return True else: return False >>> from py_entitymatching.dask.dask_black_box_blocker import DaskBlackBoxBlocker >>> bb = DaskBlackBoxBlocker() >>> bb.set_black_box_function(match_last_name) >>> status = bb.block_tuples(A.ix[0], B.ix[0]) # A, B are input tables.
-
set_black_box_function(function)¶ Sets black box function to be used for blocking.
- Parameters
function (function) – the black box function to be used for blocking .
-
Extracting Feature Vectors¶
-
py_entitymatching.dask.dask_extract_features.dask_extract_feature_vecs(candset, attrs_before=None, feature_table=None, attrs_after=None, verbose=False, show_progress=True, n_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK
This function extracts feature vectors from a DataFrame (typically a labeled candidate set).
Specifically, this function uses feature table, ltable and rtable (that is present in the candset’s metadata) to extract feature vectors.
- Parameters
candset (DataFrame) – The input candidate set for which the features vectors should be extracted.
attrs_before (list) – The list of attributes from the input candset, that should be added before the feature vectors (defaults to None).
feature_table (DataFrame) – A DataFrame containing a list of features that should be used to compute the feature vectors ( defaults to None).
attrs_after (list) – The list of attributes from the input candset that should be added after the feature vectors (defaults to None).
verbose (boolean) – A flag to indicate whether the debug information should be displayed (defaults to False).
show_progress (boolean) – A flag to indicate whether the progress of extracting feature vectors must be displayed (defaults to True).
n_chunks (int) – The number of partitions to split the candidate set. If it is set to -1, the number of partitions will be set to the number of cores in the machine.
- Returns
A pandas DataFrame containing feature vectors.
The DataFrame will have metadata ltable and rtable, pointing to the same ltable and rtable as the input candset.
Also, the output DataFrame will have three columns: key, foreign key ltable, foreign key rtable copied from input candset to the output DataFrame. These three columns precede the columns mentioned in attrs_before.
- Raises
AssertionError – If candset is not of type pandas DataFrame.
AssertionError – If attrs_before has attributes that are not present in the input candset.
AssertionError – If attrs_after has attribtues that are not present in the input candset.
AssertionError – If feature_table is set to None.
AssertionError – If n_chunks is not of type int.
Examples
>>> import py_entitymatching as em >>> from py_entitymatching.dask.dask_extract_features import dask_extract_feature_vecs >>> A = em.read_csv_metadata('path_to_csv_dir/table_A.csv', key='ID') >>> B = em.read_csv_metadata('path_to_csv_dir/table_B.csv', key='ID') >>> match_f = em.get_features_for_matching(A, B) >>> # G is the labeled dataframe which should be converted into feature vectors >>> H = dask_extract_feature_vecs(G, features=match_f, attrs_before=['title'], attrs_after=['gold_labels'])
ML-Matchers¶
-
class
py_entitymatching.dask.dask_dtmatcher.DaskDTMatcher(*args, **kwargs)¶ WARNING THIS MATCHER IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Decision Tree matcher.
- Parameters
*args,**kwargs – The arguments to scikit-learn’s Decision Tree classifier.
name (string) – The name of this matcher (defaults to None). If the matcher name is None, the class automatically generates a string and assigns it as the name.
-
fit(x=None, y=None, table=None, exclude_attrs=None, target_attr=None)¶ Fit interface for the matcher.
Specifically, there are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute.
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input feature vectors given as pandas DataFrame (defaults to None).
y (DatFrame) – The input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table.
-
predict(x=None, table=None, exclude_attrs=None, target_attr=None, append=False, return_probs=False, probs_attr=None, inplace=True, show_progress=False, n_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Predict interface for the matcher.
Specifically, there are two ways the user can call the predict method. First, interface similar to scikit-learn where the feature vectors given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) .
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
Currently, the Dask implementation supports only the cases when the table is not None and the flags inplace, append are False.
- Parameters
x (DataFrame) – The input pandas DataFrame containing only feature vectors (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors, and may be other attributes (defaults to None).
exclude_attrs (list) – A list of attributes to be excluded from the input table to get the feature vectors (defaults to None).
target_attr (string) – The attribute name where the predictions need to be stored in the input table (defaults to None).
probs_attr (string) – The attribute name where the prediction probabilities need to be stored in the input table (defaults to None).
append (boolean) – A flag to indicate whether the predictions need to be appended in the input DataFrame (defaults to False).
return_probs (boolean) – A flag to indicate where the prediction probabilities need to be returned (defaults to False). If set to True, returns the probability if the pair was a match.
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
show_progress (boolean) – A flag to indicate whether the progress of extracting feature vectors must be displayed (defaults to True).
n_chunks (int) – The number of partitions to split the candidate set. If it is set to -1, the number of partitions will be set to the number of cores in the machine.
- Returns
An array of predictions or a DataFrame with predictions updated.
-
class
py_entitymatching.dask.dask_rfmatcher.DaskRFMatcher(*args, **kwargs)¶ WARNING THIS MATCHER IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Random Forest matcher.
- Parameters
*args,**kwargs – The arguments to scikit-learn’s Random Forest classifier.
name (string) – The name of this matcher (defaults to None). If the matcher name is None, the class automatically generates a string and assigns it as the name.
-
fit(x=None, y=None, table=None, exclude_attrs=None, target_attr=None)¶ Fit interface for the matcher.
Specifically, there are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute.
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input feature vectors given as pandas DataFrame (defaults to None).
y (DatFrame) – The input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table.
-
predict(x=None, table=None, exclude_attrs=None, target_attr=None, append=False, return_probs=False, probs_attr=None, inplace=True, show_progress=False, n_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Predict interface for the matcher.
Specifically, there are two ways the user can call the predict method. First, interface similar to scikit-learn where the feature vectors given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) .
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
Currently, the Dask implementation supports only the cases when the table is not None and the flags inplace, append are False.
- Parameters
x (DataFrame) – The input pandas DataFrame containing only feature vectors (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors, and may be other attributes (defaults to None).
exclude_attrs (list) – A list of attributes to be excluded from the input table to get the feature vectors (defaults to None).
target_attr (string) – The attribute name where the predictions need to be stored in the input table (defaults to None).
probs_attr (string) – The attribute name where the prediction probabilities need to be stored in the input table (defaults to None).
append (boolean) – A flag to indicate whether the predictions need to be appended in the input DataFrame (defaults to False).
return_probs (boolean) – A flag to indicate where the prediction probabilities need to be returned (defaults to False). If set to True, returns the probability if the pair was a match.
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
show_progress (boolean) – A flag to indicate whether the progress of extracting feature vectors must be displayed (defaults to True).
n_chunks (int) – The number of partitions to split the candidate set. If it is set to -1, the number of partitions will be set to the number of cores in the machine.
- Returns
An array of predictions or a DataFrame with predictions updated.
-
class
py_entitymatching.dask.dask_nbmatcher.DaskNBMatcher(*args, **kwargs)¶ WARNING THIS MATCHER IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Naive Bayes matcher.
- Parameters
*args,**kwargs – The arguments to scikit-learn’s Naive Bayes classifier.
name (string) – The name of this matcher (defaults to None). If the matcher name is None, the class automatically generates a string and assigns it as the name.
-
fit(x=None, y=None, table=None, exclude_attrs=None, target_attr=None)¶ Fit interface for the matcher.
Specifically, there are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute.
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input feature vectors given as pandas DataFrame (defaults to None).
y (DatFrame) – The input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table.
-
predict(x=None, table=None, exclude_attrs=None, target_attr=None, append=False, return_probs=False, probs_attr=None, inplace=True, show_progress=False, n_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Predict interface for the matcher.
Specifically, there are two ways the user can call the predict method. First, interface similar to scikit-learn where the feature vectors given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) .
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
Currently, the Dask implementation supports only the cases when the table is not None and the flags inplace, append are False.
- Parameters
x (DataFrame) – The input pandas DataFrame containing only feature vectors (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors, and may be other attributes (defaults to None).
exclude_attrs (list) – A list of attributes to be excluded from the input table to get the feature vectors (defaults to None).
target_attr (string) – The attribute name where the predictions need to be stored in the input table (defaults to None).
probs_attr (string) – The attribute name where the prediction probabilities need to be stored in the input table (defaults to None).
append (boolean) – A flag to indicate whether the predictions need to be appended in the input DataFrame (defaults to False).
return_probs (boolean) – A flag to indicate where the prediction probabilities need to be returned (defaults to False). If set to True, returns the probability if the pair was a match.
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
show_progress (boolean) – A flag to indicate whether the progress of extracting feature vectors must be displayed (defaults to True).
n_chunks (int) – The number of partitions to split the candidate set. If it is set to -1, the number of partitions will be set to the number of cores in the machine.
- Returns
An array of predictions or a DataFrame with predictions updated.
-
class
py_entitymatching.dask.dask_logregmatcher.DaskLogRegMatcher(*args, **kwargs)¶ WARNING THIS MATCHER IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Logistic Regression matcher.
- Parameters
*args,**kwargs – THe Arguments to scikit-learn’s Logistic Regression classifier.
name (string) – The name of this matcher (defaults to None). If the matcher name is None, the class automatically generates a string and assigns it as the name.
-
fit(x=None, y=None, table=None, exclude_attrs=None, target_attr=None)¶ Fit interface for the matcher.
Specifically, there are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute.
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input feature vectors given as pandas DataFrame (defaults to None).
y (DatFrame) – The input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table.
-
predict(x=None, table=None, exclude_attrs=None, target_attr=None, append=False, return_probs=False, probs_attr=None, inplace=True, show_progress=False, n_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Predict interface for the matcher.
Specifically, there are two ways the user can call the predict method. First, interface similar to scikit-learn where the feature vectors given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) .
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
Currently, the Dask implementation supports only the cases when the table is not None and the flags inplace, append are False.
- Parameters
x (DataFrame) – The input pandas DataFrame containing only feature vectors (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors, and may be other attributes (defaults to None).
exclude_attrs (list) – A list of attributes to be excluded from the input table to get the feature vectors (defaults to None).
target_attr (string) – The attribute name where the predictions need to be stored in the input table (defaults to None).
probs_attr (string) – The attribute name where the prediction probabilities need to be stored in the input table (defaults to None).
append (boolean) – A flag to indicate whether the predictions need to be appended in the input DataFrame (defaults to False).
return_probs (boolean) – A flag to indicate where the prediction probabilities need to be returned (defaults to False). If set to True, returns the probability if the pair was a match.
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
show_progress (boolean) – A flag to indicate whether the progress of extracting feature vectors must be displayed (defaults to True).
n_chunks (int) – The number of partitions to split the candidate set. If it is set to -1, the number of partitions will be set to the number of cores in the machine.
- Returns
An array of predictions or a DataFrame with predictions updated.
-
class
py_entitymatching.dask.dask_xgboost_matcher.DaskXGBoostMatcher(*args, **kwargs)¶ WARNING THIS MATCHER IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK
XGBoost matcher.
- Parameters
*args,**kwargs – The arguments to XGBoost classifier.
name (string) – The name of this matcher (defaults to None). If the matcher name is None, the class automatically generates a string and assigns it as the name.
-
fit(x=None, y=None, table=None, exclude_attrs=None, target_attr=None)¶ Fit interface for the matcher.
Specifically, there are two ways the user can call the fit method. First, interface similar to scikit-learn where the feature vectors and target attribute given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) and the target attribute.
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
- Parameters
x (DataFrame) – The input feature vectors given as pandas DataFrame (defaults to None).
y (DatFrame) – The input target attribute given as pandas DataFrame with a single column (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors and target attribute (defaults to None).
exclude_attrs (list) – The list of attributes that should be excluded from the input table to get the feature vectors.
target_attr (string) – The target attribute in the input table.
-
predict(x=None, table=None, exclude_attrs=None, target_attr=None, append=False, return_probs=False, probs_attr=None, inplace=True, show_progress=False, n_chunks=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Predict interface for the matcher.
Specifically, there are two ways the user can call the predict method. First, interface similar to scikit-learn where the feature vectors given as projected DataFrame. Second, give the DataFrame and explicitly specify the feature vectors (by specifying the attributes to be excluded) .
A point to note is all the input parameters have a default value of None. This is done to support both the interfaces in a single function.
Currently, the Dask implementation supports only the cases when the table is not None and the flags inplace, append are False.
- Parameters
x (DataFrame) – The input pandas DataFrame containing only feature vectors (defaults to None).
table (DataFrame) – The input pandas DataFrame containing feature vectors, and may be other attributes (defaults to None).
exclude_attrs (list) – A list of attributes to be excluded from the input table to get the feature vectors (defaults to None).
target_attr (string) – The attribute name where the predictions need to be stored in the input table (defaults to None).
probs_attr (string) – The attribute name where the prediction probabilities need to be stored in the input table (defaults to None).
append (boolean) – A flag to indicate whether the predictions need to be appended in the input DataFrame (defaults to False).
return_probs (boolean) – A flag to indicate where the prediction probabilities need to be returned (defaults to False). If set to True, returns the probability if the pair was a match.
inplace (boolean) – A flag to indicate whether the append needs to be done inplace (defaults to True).
show_progress (boolean) – A flag to indicate whether the progress of extracting feature vectors must be displayed (defaults to True).
n_chunks (int) – The number of partitions to split the candidate set. If it is set to -1, the number of partitions will be set to the number of cores in the machine.
- Returns
An array of predictions or a DataFrame with predictions updated.
Tuners for the Dask-based Commands¶
Downsampling¶
-
py_entitymatching.tuner.tuner_down_sample.tuner_down_sample(ltable, rtable, size, y_param, seed, rem_stop_words, rem_puncs, n_bins=50, sample_proportion=0.1, repeat=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Tunes the parameters for down sampling command implemented using Dask.
Given the input tables and the parameters for Dask-based down sampling command, this command returns the configuration including whether the input tables need to be swapped, the number of left table chunks, and the number of right table chunks. It uses “Staged Tuning” approach to select the configuration setting. The key idea of this approach select the configuration for one parameter at a time.
Conceptually, this command performs the following steps. First, it samples the left table and down sampled rtable using stratified sampling. Next, it uses the sampled tables to decide if they need to be swapped or not (by running the down sample command and comparing the runtimes). Next, it finds the number of rtable partitions using the sampled tables (by trying the a fixed set of partitions and comparing the runtimes). The number of partitions is selected to be the number before which the runtime starts increasing. Then it finds the number of right table partitions similar to selecting the number of left table partitions. while doing this, set the number of right table partitions is set to the value found in the previous step. Finally, it returns the configuration setting back to the user as a triplet (x, y, z) where x indicates if the tables need to be swapped or not, y indicates the number of left table partitions (if the tables need to be swapped, then this indicates the number of left table partitions after swapping), and z indicates the number of down sampled right table partitions.
- Parameters
ltable (DataFrame) – The left input table, i.e., table A.
rtable (DataFrame) – The right input table, i.e., table B.
size (int) – The size that table B should be down sampled to.
y_param (int) – The parameter to control the down sample size of table A. Specifically, the down sampled size of table A should be close to size * y_param.
seed (int) – The seed for the pseudo random number generator to select the tuples from A and B (defaults to None).
rem_stop_words (boolean) – A flag to indicate whether a default set of stop words must be removed.
rem_puncs (boolean) – A flag to indicate whether the punctuations must be removed from the strings.
n_bins (int) – The number of bins to be used for stratified sampling.
sample_proportion (float) – The proportion used to sample the tables. This value is expected to be greater than 0 and less thank 1.
repeat (int) – The number of times to execute the down sample command while selecting the values for the parameters.
- Returns
A tuple containing 3 values. For example if the tuple is represented as (x, y, z) then x indicates if the tables need to be swapped or not, y indicates the number of left table partitions (if the tables need to be swapped, then this indicates the number of left table partitions after swapping), and z indicates the number of down sampled right table partitions.
Examples
>>> from py_entitymatching.tuner.tuner_down_sample import tuner_down_sample >>> (swap_or_not, n_ltable_chunks, n_sample_rtable_chunks) = tuner_down_sample(ltable, rtable, size, y_param, seed, rem_stop_words, rem_puncs)
Overlap Blocker¶
-
py_entitymatching.tuner.tuner_overlap_blocker.tuner_overlap_blocker(ltable, rtable, l_key, r_key, l_overlap_attr, r_overlap_attr, rem_stop_words, q_val, word_level, overlap_size, ob_obj, n_bins=50, sample_proportion=0.1, seed=0, repeat=1)¶ WARNING THIS COMMAND IS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
Tunes the parameters for blocking two tables command implemented using Dask.
Given the input tables and the parameters for Dask-based overlap blocker command, this command returns the configuration including whether the input tables need to be swapped, the number of left table chunks, and the number of right table chunks. It uses “Staged Tuning” approach to select the configuration setting. The key idea of this approach select the configuration for one parameter at a time.
Conceptually, this command performs the following steps. First, it samples the left table and rtable using stratified sampling. Next, it uses the sampled tables to decide if they need to be swapped or not (by running the down sample command and comparing the runtimes). Next, it finds the number of rtable partitions using the sampled tables (by trying the a fixed set of partitions and comparing the runtimes). The number of partitions is selected to be the number before which the runtime starts increasing. Then it finds the number of right table partitions similar to selecting the number of left table partitions. while doing this, set the number of right table partitions is set to the value found in the previous step. Finally, it returns the configuration setting back to the user as a triplet (x, y, z) where x indicates if the tables need to be swapped or not, y indicates the number of left table partitions (if the tables need to be swapped, then this indicates the number of left table partitions after swapping), and z indicates the number of right table partitions.
- Parameters
ltable (DataFrame) – The left input table.
rtable (DataFrame) – The right input table.
l_overlap_attr (string) – The overlap attribute in left table.
r_overlap_attr (string) – The overlap attribute in right table.
rem_stop_words (boolean) – A flag to indicate whether stop words (e.g., a, an, the) should be removed from the token sets of the overlap attribute values (defaults to False).
q_val (int) – The value of q to use if the overlap attributes values are to be tokenized as qgrams (defaults to None).
word_level (boolean) – A flag to indicate whether the overlap attributes should be tokenized as words (i.e, using whitespace as delimiter) (defaults to True).
overlap_size (int) – The minimum number of tokens that must overlap.
ob_obj (OverlapBlocker) – The object used to call commands to block two tables and a candidate set
n_bins (int) – The number of bins to be used for stratified sampling.
sample_proportion (float) – The proportion used to sample the tables. This value is expected to be greater than 0 and less thank 1.
repeat (int) – The number of times to execute the down sample command while selecting the values for the parameters.
- Returns
A tuple containing 3 values. For example if the tuple is represented as (x, y, z) then x indicates if the tables need to be swapped or not, y indicates the number of left table partitions (if the tables need to be swapped, then this indicates the number of left table partitions after swapping), and z indicates the number of right table partitions.
Examples
>>> from py_entitymatching.tuner.tuner_overlap_blocker import tuner_overlap_blocker >>> from py_entitymatching.dask.dask_overlap_blocker import DaskOverlapBlocker >>> obj = DaskOverlapBlocker() >>> (swap_or_not, n_ltable_chunks, n_sample_rtable_chunks) = tuner_overlap_blocker(ltable, rtable, 'id', 'id', "title", "title", rem_stop_words=True, q_val=None, word_level=True, overlap_size=1, ob_obj=obj)
Matcher Combiner¶
-
class
py_entitymatching.matchercombiner.matchercombiner.MajorityVote¶ THIS CLASS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
The goal of this combiner is to combine a list of predictions from multiple matchers to produce a consolidated prediction. In this majority voting-based combining, the prediction that occurs most is returned as the consolicated prediction. If there is no clear winning prediction (for example, 0 and 1 occuring equal number of times) then 0 is returned.
Implementation wise, there should be a combiner command to which an object of this class must be given as a parameter. Based on this parameter, the combiner command will use this object to combine the predictions.
-
combine(predictions)¶ Combine a list of predictions from matchers using majority voting.
- Parameters
predictions (DataFrame) – A table containing predictions from multiple matchers.
- Returns
A list of consolidated predictions.
Examples
>>> dt = DTMatcher() >>> rf = RFMatcher() >>> nb = NBMatcher() >>> dt.fit(table=H, exclude_attrs=['_id', 'l_id', 'r_id'], target_attr='label') # H is training set containing feature vectors >>> dt.predict(table=L, exclude_attrs=['id', 'l_id', 'r_id'], append=True, inplace=True, target_attr='dt_predictions') # L is the test set for which we should get predictions. >>> rf.fit(table=H, exclude_attrs=['_id', 'l_id', 'r_id'], target_attr='label') >>> rf.predict(table=L, exclude_attrs=['id', 'l_id', 'r_id'], append=True, inplace=True, target_attr='rf_predictions') >>> nb.fit(table=H, exclude_attrs=['_id', 'l_id', 'r_id'], target_attr='label') >>> nb.predict(table=L, exclude_attrs=['id', 'l_id', 'r_id'], append=True, inplace=True, target_attr='nb_predictions') >>> mv_combiner = MajorityVote() >>> L['consol_predictions'] = mv_combiner.combine(L[['dt_predictions', 'rf_predictions', 'nb_predictions']])
-
-
class
py_entitymatching.matchercombiner.matchercombiner.WeightedVote(weights=None, threshold=None)¶ THIS CLASS EXPERIMENTAL AND NOT TESTED. USE AT YOUR OWN RISK.
The goal of this combiner is to combine a list of predictions from multiple matchers to produce a consolidated prediction. In this weighted voting-based combining, each prediction is given a weight, we compute a weighted sum of these predictions and compare the result to a threshold. If the result is greater than or equal to the threshold then the consolidated prediction is returned as a match (i.e., 1) else returned as a no-match.
Implementation wise, there should be a combiner command to which an object of this class must be given as a parameter. Based on this parameter, the combiner command will use this object to combine the predictions.
-
combine(predictions)¶ Combine a list of predictions from matchers using weighted voting.
- Parameters
predictions (DataFrame) – A table containing predictions from multiple matchers.
- Returns
A list of consolidated predictions.
Examples
>>> dt = DTMatcher() >>> rf = RFMatcher() >>> nb = NBMatcher() >>> dt.fit(table=H, exclude_attrs=['_id', 'l_id', 'r_id'], target_attr='label') # H is training set containing feature vectors >>> dt.predict(table=L, exclude_attrs=['id', 'l_id', 'r_id'], append=True, inplace=True, target_attr='dt_predictions') # L is the test set for which we should get predictions. >>> rf.fit(table=H, exclude_attrs=['_id', 'l_id', 'r_id'], target_attr='label') >>> rf.predict(table=L, exclude_attrs=['id', 'l_id', 'r_id'], append=True, inplace=True, target_attr='rf_predictions') >>> nb.fit(table=H, exclude_attrs=['_id', 'l_id', 'r_id'], target_attr='label') >>> nb.predict(table=L, exclude_attrs=['id', 'l_id', 'r_id'], append=True, inplace=True, target_attr='nb_predictions') >>> wv_combiner = WeightedVote(weights=[0.1, 0.2, 0.1], threshold=0.2) >>> L['consol_predictions'] = wv_combiner.combine(L[['dt_predictions', 'rf_predictions', 'nb_predictions']])
-